この記事はレコチョク Advent Calendar 2025 の17日目の記事となります。
はじめに
はじめまして。私はレコチョクの社内のDX化の推進をしているチームに所属しております。
私事ですが先日、来年の4月に行われるゾンビランドサガというアイドルアニメのライブのチケットに当選いたしました。 ライブに当選するのが初めてで、今からとっても楽しみです!!
※こちらの記事で紹介されるWebページはすべてサンプルです。
さて、私は業務上しばしばPower Automate Desktop(以下PAD)を使用してWebスクレイピングを行っています。 今回はPADでWebスクレイピングを行う際に遭遇する課題と、CSSの疑似クラスを活用した課題の解決方法をご紹介します。
Power Automate Desktopでのスクレイピングの課題
PADでWebスクレイピングを実装していると、以下のような課題に直面することがあります。
課題1: ボタンの状態判定が難しい
Webページのページネーションで「次へ」ボタンを自動でクリックし続けたい場合を考えてみましょう。
多くのWebサイトでは、最終ページに到達すると「次へ」ボタンがクリックできなくなったり、HTMLの要素が変化したりします。
例)最終ページに到達すると状態が変わるボタンのイメージ①

例)最終ページに到達すると状態が変わるボタンのイメージ②

しかし、見た目が変わらなかったり、HTML要素が変わらない場合があります。
例)最終ページに到達しても変わらないボタンのイメージ①

例)最終ページに到達しても変わらないボタンのイメージ②

このようなサイトでは、PADの「要素の存在を確認する」アクションだけでは、そのボタンが「クリック可能」なのか「クリック不可」なのかを判別できません。結果として、最終ページに到達してもボタンの状態判定ができない場合があります。
課題2: 複合的な情報を持つHTMLテーブルの一括取得
PADの「HTMLテーブル全体を抽出する」機能は、1つのセルに1つの情報という単純な表であれば問題なくデータを取得できます。
しかし、実際のWebサイトでは、1つのテーブルセル内に複数の要素(テキスト、リンク、ボタンなど)が混在している表も存在します。
例)複合的な情報を持つHTMLテーブルのイメージ

このような複雑な構造のテーブルでは、PADの標準機能では以下の問題が発生します
問題点:
- セル内の複数情報が1つの文字列として結合されてしまう
- リンク先のURLなど、表示されていない属性情報が取得できない
PADのWebスクレイピングの課題の解決策
このようなPADのWebスクレイピングの課題を、今回はCSSの疑似クラスを使用して解決する方法をご紹介いたします。
PADでスクレイピングを行う際のCSS基礎知識
まずは、PADでスクレイピングを行うにあたって必要なCSSの基礎知識についてご紹介させて頂きます。
CSSセレクターの基本
PADでWebスクレイピングを行う際に使用するCSSセレクターには、以下の基本的な記法があります。
| 記法 | 説明 | 記述例 | 対象となる要素 |
|---|---|---|---|
#id名 |
ID属性で要素を指定 | #productTable_next |
id="productTable_next"の要素 |
.class名 |
class属性で要素を指定 | .disabled |
class="disabled"の要素 |
要素名 |
HTMLタグで要素を指定 | li, a |
<li>タグ、<a>タグ |
要素名#id名 |
タグとIDの組み合わせ | li#productTable_next |
<li id="productTable_next"> |
要素名.class名 |
タグとclassの組み合わせ | li.disabled |
<li class="disabled"> |
これらの基本的なセレクターは、ChromeやEdge等のディベロッパーツールで確認できる情報を基に作成することが可能です。
PADの「UI要素の追加」機能では、ディベロッパーツールで確認できる通常のHTML要素(IDやclass)を自動取得することができます。
一方、要素の状態(有効/無効)や位置(何番目)などの動的な情報は取得できないため、細かく要素を指定したい場合は疑似クラスを手動でセレクターに追加する必要があります。
CSSの疑似クラスの基本概念
疑似クラスは、通常のHTMLには記述されていない「要素の状態」や「要素の位置」といった情報を基に、より細かく要素を選択できる仕組みです。
これにより単に「どの要素を選択するか」だけでなく、「どんな状態の要素を選択するか」の指定が可能になり、指定の幅が広がります。
疑似クラスを活用することで、動的なWebページの要素状態を判定条件に加えることができ、より柔軟で確実なWebスクレイピングが可能になります。
例えば、以下のような疑似クラスが存在します。
状態を判定する疑似クラス
| 疑似クラス | 説明 | PADでの活用場面 |
|---|---|---|
:enabled |
有効な要素 | クリック可能なボタンの判定 |
:disabled |
無効な要素 | クリック不可なボタンの判定 |
:checked |
チェック済み | チェックボックスの状態確認 |
:focus |
フォーカス中 | 入力フィールドの選択状態 |
位置を判定する疑似クラス
| 疑似クラス | 説明 | PADでの活用場面 |
|---|---|---|
:first-child |
最初の子要素 | リストの先頭項目取得 |
:last-child |
最後の子要素 | リストの末尾項目取得 |
:nth-child(n) |
n番目の子要素 | 特定順位の要素取得 |
今回は、この「状態を判別する疑似クラス」と「位置を判別する疑似クラス」を使用して先述した課題を解決していきましょう!
課題 解決策
課題1: ボタンの状態判定を実現
疑似クラスを活用して、「次へ」ボタンが無効化されているかどうか確認できる仕組みを作成してみます。
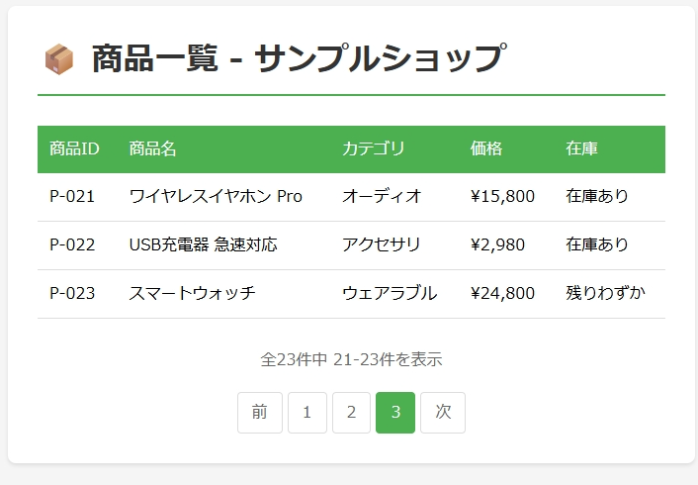
こちらのページの「次へ」ボタンのUI要素を取得した場合、セレクターは下記の通りになります。
通常の方法で取得されたセレクター
a[aria-label="次のページ"]単純にクリックするだけであればこちらのセレクターで問題ありません。 しかし、このままではクリック可能かどうかの判定は行えません。
1.セレクターを変更して状態確認を実現する
実際のセレクター設定を確認してみましょう 最終ページでディベロッパーツールを確認すると、以下のようなHTMLになっています:
<li class="next disabled" id="productTable_next">
<a href="#" aria-label="次のページ">次</a>
</li>中間ページではdisabledクラスがない状態
<li class="next" id="productTable_next">
<a href="#" aria-label="次のページ">次</a>
</li>PADで通常通り要素を取得すると <a>タグが選択されますが、下記の要因により「要素が常に存在する」と判断され状態取得がうまくいきません。
<a>タグ自体は最終ページでも存在し続ける- 親要素の
<li>タグに付与されるdisabledクラスは考慮されない
解決策:否定疑似クラス「:not()」を活用
ポイント
:not()は疑似クラスであり、「特定の条件に合致しない要素」を選択できます。
これにより「disabledクラスが付いていない次へボタン」つまり「クリック可能な状態の次へボタン」のみを検出できるようになります。
最終ページではdisabledクラスが付与されるため、このセレクターに合致する要素が存在しなくなり、「次へ」ボタンがクリックできるかどうかの判定が実現できます。
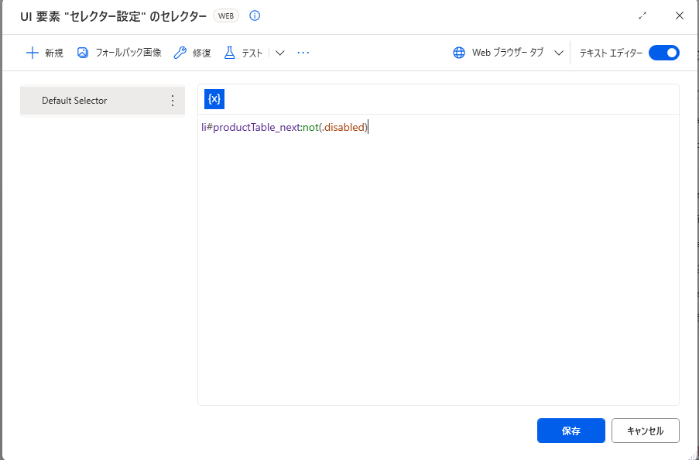
このようなポイントを考慮した上で変更したセレクターは下記のようになります
変更後のセレクター
li#productTable_next:not(.disabled)このセレクターの構成:
li#productTable_next→ IDで要素を特定(通常のセレクター):not(.disabled)→disabledクラスを持たない要素のみを選択(否定疑似クラス)
2.セレクターの編集方法
疑似クラスを使用しないでセレクターを設定する場合は、通常通り「UI要素の追加」からセレクターを作成すれば問題ありません。
疑似クラスを使用する場合は、「UI要素の追加」を行った後にセレクターを編集する必要があります。 セレクターの編集画面を開き、右上の「テキストエディター」をクリックします。
先ほど解説いたしました変更後のセレクターを記載すれば完成です。 保存前に「テスト」を実際に行ってみて想定通りの動きができるか確認してみてくださいね!
課題2:複合的な情報を持つHTMLテーブルの一括取得
次に下記ページのような、複合的な情報を持つテーブルから情報を分割するかつURLを一括取得する方法を作成していきます。
今回は「Webページからデータを抽出する」というPADのアクションを使用して、データの一括取得を行います。
通常の方法で一括取得されたデータイメージ

「Webページからデータを抽出する」アクションにて「HTMLテーブル全体」を抽出した場合、上記のような結果になるため、「書籍ID/タイトル」の列の情報は結合され、URLの情報は取得できません。
1. データ構造の分析
まずは取得対象のHTMLテーブルの構造を詳しく確認してみます。 今回の出力対象のページは以下のような構造になっていると仮定します。
データ構造イメージ
<table id="bookListTable" class="dataTable">
<tbody>
<tr>
<td>
<span class="book-code">BOOK-2024-0001</span>
<a href="/book/detail/?id=20240001" class="book-title-link">Pythonで学ぶデータ分析入門</a>
</td>
<td>山田 太郎</td>
</tr>
<!-- 以下、同様の構造で続く -->
</tbody>
</table>
取得したい情報とCSSセレクターの対応
ここで必要な情報を取得するのに役立つのが位置を判定する疑似クラスになります。 それぞれ、以下のCSSセレクターを使用して抽出を行います。
| 取得したい情報 | CSSセレクター | HTML要素の場所 | 取得する属性 |
|---|---|---|---|
| 書籍ID | td:nth-child(1) span.book-code |
1列目のspan要素内 | テキスト |
| タイトル | td:nth-child(1) a |
1列目のa要素内 | テキスト |
| 詳細ページURL | td:nth-child(1) a |
1列目のa要素 | href |
| 著者名 | td:nth-child(2) |
2列目のtd要素内 | テキスト |
通常の「HTMLテーブル全体を抽出」では、書籍IDとタイトルが「BOOK-2024-0001 Pythonで学ぶデータ分析入門」のように結合された1つの文字列として取得されてしまいます。また、リンクのURL情報は取得できません。
疑似クラス :nth-child() を使用することで下記の挙動を実現することができます。
- 列の指定 →
td:nth-child(1)で1列目、td:nth-child(2)で2列目を明確に指定 - 要素の特定 → さらに
span.book-codeやaで、セル内の特定要素を狙い撃ち - 属性の取得 →
href属性を指定してURL情報も取得可能
これにより、複合的な情報を持つテーブルから、それぞれの要素を構造化されたデータとして分離・取得できるようになります。
2. PADでの実装手順
では実際にPADのアクションの設定をしていきます。
「抽出プレビュー」が表示されたら、「詳細設定」をクリックしてください。

「詳細設定」が表示されましたら下記を例に設定を行います。

ポイント解説
- 抽出には、「テーブル」を設定します。
- 基本CSSセレクター には、テーブルの各行(
tr要素)を指定します - Own Text は要素内のテキストを取得
- Href はリンクのURL属性を取得
:nth-child()疑似クラスで列を明確に指定することで、複合セルから個別の要素を抽出
このように設定することで、下記のようなイメージで出力することが可能です。

まとめ
CSSの疑似クラスを活用することで、PADでのスクレイピングがより柔軟かつ効率的になります。
疑似クラスはCSSの標準機能であり、すべてのブラウザで利用可能です。 PADのWebスクレイピングで課題を感じている方は、ぜひ疑似クラスの活用を検討してみてください。
業務の自動化を進める中で、このような小さな工夫が大きな効率化につながることがあります。 今後もDX推進の一環として、様々な技術の組み合わせを模索していきたいと思います。
明日の レコチョク Advent Calendar 2025 は18日目 『Androidの加速度センサーで操作するUnityゲームを作ってみた』です。お楽しみに!
山田

