はじめに
この記事のオリジナルは 2017/02/28 にレコチョク社内向けに公開したものです。多少情報が古くなっているかもしれません。ご了承ください。
改行問題
改行問題、とは例えば以下のような状態のことです。

「リリース」の「リリ」で改行されています。 本当ならば、「リリース」という単語の途中で改行をしてほしくありません。
この、「改行させない」という処理はWeb のコード的には難しくありません。 例えば、以下のような span タグで単語ごとに区切ってあげれば、改行は span タグ単位になります。
アカシック「愛×Happy×クレイジー」リリース記念ファン参加型プロジェクト
↓
<span style="display: inline-block;">アカシック</span>
<span style="display: inline-block;">「愛</span>
<span style="display: inline-block;">×</span>
<span style="display: inline-block;">Happy</span>
<span style="display: inline-block;">×</span>
<span style="display: inline-block;">クレイジー」</span>
<span style="display: inline-block;">リリース</span>
<span style="display: inline-block;">記念</span>
<span style="display: inline-block;">ファン</span>
<span style="display: inline-block;">参加型</span>
<span style="display: inline-block;">プロジェクト</span>
全てのプロジェクトタイトル(及びそれに類するもの)に人力で区切り位置を入れれば解決するのですが、これは大変な作業です。
そこで、先輩よりこれを機械学習で解決する(かもしれない)ツール budou の検証を依頼されました。
ライブラリ budou とは?
budou とはGoogle から出ている「自動的に文章を良い感じの文節で区切ってくれるライブラリ」です。 例えば、上のような文章を引数で渡すと、文章をいい感じで区切って配列で渡してくれる…らしいです。 早速使ってみましょう。
作者のブログ に使い方が詳細に書かれているので、それに従って設定をしていきます。
Google クラウド自然言語処理API に登録
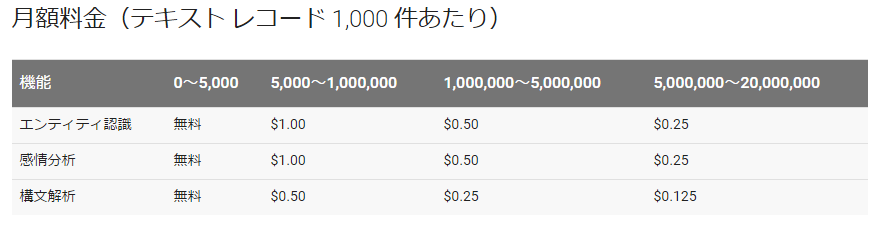
budou は Google クラウド自然言語処理API という有償の API を呼び出しています。 これは、住所やクレジットカードの情報を入れないと使うことが出来ません。
料金表ページ によると、5000回までは無料で使えるらしいです。
先ほどの作者ブログに図付きで詳細に説明してありますので、こちらの記事では登録については割愛します。
最終的に、認証情報が入った JSON ファイルをローカルに保存すれば OK です。
Budou をインストール
続いて、Budou のインストールを行います。 Python であれば pip コマンドで簡単にインストールができます。
$ pip install budou
Github を見ると、最新のバージョンは 0.2.1 のようです。
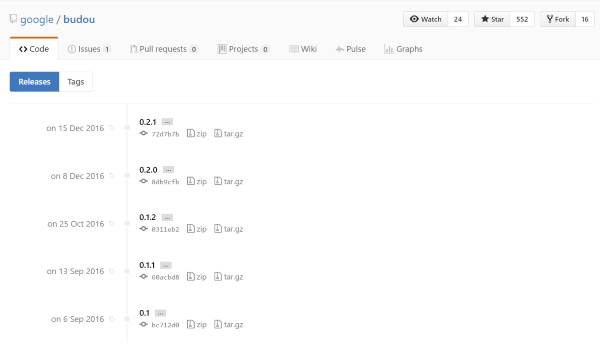
pip ではどのバージョンがインストールされるのでしょうか。

0.2.2 がインストールされました。…え? …見なかったことにしましょう。
実際に使ってみる
サンプルコードで試す
簡単なコードを書いて試してみましょう。 ちなみに、サンプルコードは Python2 ですが、3 でも問題なく動きました 作者のブログにあったサンプルを 3 で書き直して動かしてみました。
import budou
parser = budou.authenticate('key.json') # Google クラウド自然言語処理API のキー
output = parser.parse('アカシック「愛×Happy×クレイジー」リリース記念ファン参加型プロジェクト')
print(output['html_code'])
実行してみます。
$ python budou_test.py
<span class="ww">アカシック「</span><span class="ww">愛</span><span class="ww">×</span><span class="ww">Happy</span><span class="ww">×</span><span class="ww">クレイジー」</span><span class="ww">リリース</span><span class="ww">記念</span><span class="ww">ファン</span><span class="ww">参加型</span><span class="ww">プロジェクト</span>
3秒ほどかけて、出力が出てきました。API と通信するので、その部分で結構時間がかかるみたいです。
span タグで分けられた状態で入力文が出てきました。 第二引数で span タグのクラスは変更できるみたいです。 試しに大草原にしてみます。
import budou
parser = budou.authenticate('key.json') # Google クラウド自然言語処理API のキー
output = parser.parse('アカシック「愛×Happy×クレイジー」リリース記念ファン参加型プロジェクト', 'wwwwwwwww')
print(output['html_code'])
実行してみます。
$ python budou_test.py
<span class="ww">アカシック「</span><span class="ww">愛</span><span class="ww">×</span><span class="ww">Happy</span><span class="ww">×</span><span class="ww">クレイジー」</span><span class="ww">リリース</span><span class="ww">記念</span><span class="ww">ファン</span><span class="ww">参加型</span><span class="ww">プロジェクト</span>
変わってません。
そういえば、budou は自動で実行ディレクトリにキャッシュを生成するようになっています。 試しに、キャッシュを消して実行してみましょう
$ ls
budou-cache.shelve.bak budou-cache.shelve.dir
budou-cache.shelve.dat budou_test.py key.json
$ rm budou-cache.shelve.*
$ python budou_test.py
<span class="wwwwwwwww">アカシック「</span><span class="wwwwwwwww">愛</span><span class="wwwwwwwww">×</span><span class="wwwwwwwww">Happy</span><span class="wwwwwwwww">×</span><span class="wwwwwwwww">クレイジー」</span><span class="wwwwwwwww">リリース</span><span class="wwwwwwwww">記念</span><span class="wwwwwwwww">ファン</span><span class="wwwwwwwww">参加型</span><span class="wwwwwwwww">プロジェクト</span>
ちゃんと大草原になりました。いちいちキャッシュを消さないと行けないのは少し面倒ですね。
WIZY に組み込んでみる
実際に WIZY のタイトル表示部分にこの処理を組み込んでみました。 ソースコードは長くなるので割愛します。
このように、変な箇所で改行されることはなくなりました。 (このスクリーンショットだと効果が今ひとつ伝わらないですね :-)

また、画面幅を変えるとちゃんとそれに合わせて適切な位置で改行してくれます。 Web サイトはPCやSPで色んな画面幅に対応しないといけないので、この確認はとても大事です。

単語の区切り位置を検証
簡単に使えそう、ということは分かりました。 次に、生成される区切りが人が見て自然かどうか見ます。
データ沢山入れて試してみる
WIZY 現行プロジェクトを一通り入れて試してみます。
'KEYTALK『PARADISE』発売記念! 「リアル謎解きゲーム」プロジェクト',
'KEYTALK × ドラマチック謎解きゲーム',
'WORLD ORDERが目の前でダンス!360度VRで、今までにない視覚体験を!',
'WORLD ORDER×TISSOT×レコチョク・ラボがコラボした、最先端360度VR動画制作をみんなで応援しよう!',
'「エジソン」メインパーソナリティ花江夏樹、日高里菜と番組テーマソングを作ろう!',
'文化放送のアニラジ看板番組「エジソン」のメインパーソナリティ花江夏樹、日高里菜と作る番組テーマソング制作プロジェクト!',
'オリジナルグラス制作プロジェクト',
'「一息つきたい時にお酒でも飲みながら聴いて欲しい」TAKUROの想いが詰まったWIZY限定オリジナルグラスセットを制作!',
'JIN AKANISHIがVRで目の前に迫る。今までにない新しいライブ体験',
'3/15発売のJIN AKANISHIライブDVD&Blu-rayの初回限定盤を期間限定でWIZYで予約受付中!',
'アカシック「愛×Happy×クレイジー」リリース記念ファン参加型プロジェクト',
'アカシック1st シングルリリース記念、MUSIC VIDEO・スペシャルライブ・トークイベントを共に創りあげよう!',
'JFL×Amadana Music オリジナル・ラジオ制作プロジェクト',
'ラジオと音楽を愛する人たちに、もっと素敵な空間を。Bluetoothスピーカーとしても使えるラジオをつくろう!'
'もう一つの虚無病。アナザーストーリー ピクチャーブック「nothingness」',
'秋田ひろむが書き下ろした”もう一つの”虚無病ストーリー「nothingness」が制作決定。',
'“音楽の街”渋谷のハロウィンをクリーンに! シブラジから渋谷を愛するみなさんへ',
'地域密着×世界最先端の放送局が賛同する"ハロウィンごみゼロ大作戦 in 渋谷"をラジオパーソナリティと一緒に盛り上げよう',
'AIから頑張るママたちへ。PREMIUMママプロジェクト@日本武道館',
'全国のママたちにもっとライブを楽しんでもらうため、11/1(火)の武道館公演で、ママも親子も楽しめるエリアをつくりたい!'
<span class="ww">KEYTALK『</span><span class="ww">PARADISE』</span><span class="ww">発売</span><span class="ww">記念!</span> 「<span class="ww">リアル</span><span class="ww">謎</span><span class="ww">解き</span><span class="ww">ゲーム」</span><span class="ww">プロジェクト</span>
<span class="ww">KEYTALK</span> <span class="ww">×</span> <span class="ww">ドラマチック</span><span class="ww">謎</span><span class="ww">解き</span><span class="ww">ゲーム</span>
<span class="ww">WORLD</span> <span class="ww">ORDERが</span><span class="ww">目の</span><span class="ww">前で</span><span class="ww">ダンス!</span><span class="ww">360度</span><span class="ww">VRで、</span><span class="ww">今までに</span><span class="ww">ない</span><span class="ww">視覚</span><span class="ww">体験を!</span>
<span class="ww">WORLD</span> <span class="ww">ORDER</span><span class="ww">×</span><span class="ww">TISSOT</span><span class="ww">×</span><span class="ww">レコチョク・</span><span class="ww">ラボが</span><span class="ww">コラボした、</span><span class="ww">最</span><span class="ww">先端</span><span class="ww">360度</span><span class="ww">VR</span><span class="ww">動画</span><span class="ww">制作を</span><span class="ww">みんなで</span><span class="ww">応援しよう!</span>
<span class="ww">「エジソン」</span><span class="ww">メイン</span><span class="ww">パーソナリティ</span><span class="ww">花江</span><span class="ww">夏樹、</span><span class="ww">日</span><span class="ww">高</span><span class="ww">里菜と</span><span class="ww">番組</span><span class="ww">テーマ</span><span class="ww">ソングを</span><span class="ww">作</span><span class="ww">ろう!</span>
<span class="ww">文化</span><span class="ww">放送の</span><span class="ww">アニラジ</span><span class="ww">看板</span><span class="ww">番組「</span><span class="ww">エジソン」の</span><span class="ww">メイン</span><span class="ww">パーソナリティ</span><span class="ww">花江</span><span class="ww">夏樹、</span><span class="ww">日</span><span class="ww">高</span><span class="ww">里菜と</span><span class="ww">作る</span><span class="ww">番組</span><span class="ww">テーマ</span><span class="ww">ソング</span><span class="ww">制作</span><span class="ww">プロジェクト!</span>
<span class="ww">オリジナル</span><span class="ww">グラス</span><span class="ww">制作</span><span class="ww">プロジェクト</span>
<span class="ww">「一息</span><span class="ww">つきたい</span><span class="ww">時に</span><span class="ww">お</span><span class="ww">酒でも</span><span class="ww">飲みながら</span><span class="ww">聴いて欲しい」</span><span class="ww">TAKUROの</span><span class="ww">想いが</span><span class="ww">詰まった</span><span class="ww">WIZY</span><span class="ww">限定</span><span class="ww">オリジナル</span><span class="ww">グラス</span><span class="ww">セットを</span><span class="ww">制作!</span>
<span class="ww">JIN</span> <span class="ww">AKANISHIが</span><span class="ww">VRで</span><span class="ww">目の</span><span class="ww">前に</span><span class="ww">迫る。</span><span class="ww">今までに</span><span class="ww">ない</span><span class="ww">新しい</span><span class="ww">ライブ</span><span class="ww">体験</span>
<span class="ww">3/15</span><span class="ww">発売の</span><span class="ww">JIN</span> <span class="ww">AKANISHI</span><span class="ww">ライブ</span><span class="ww">DVD&Blu-</span><span class="ww">rayの</span><span class="ww">初回</span><span class="ww">限定盤を</span><span class="ww">期間</span><span class="ww">限定で</span><span class="ww">WIZYで</span><span class="ww">予約</span><span class="ww">受付中!</span>
<span class="ww">アカシック「</span><span class="ww">愛</span><span class="ww">×</span><span class="ww">Happy</span><span class="ww">×</span><span class="ww">クレイジー」</span><span class="ww">リリース</span><span class="ww">記念</span><span class="ww">ファン</span><span class="ww">参加型</span><span class="ww">プロジェクト</span>
<span class="ww">アカシック</span><span class="ww">1st</span> <span class="ww">シングル</span><span class="ww">リリース</span><span class="ww">記念、</span><span class="ww">MUSIC</span> <span class="ww">VIDEO・</span><span class="ww">スペシャル</span><span class="ww">ライブ・</span><span class="ww">トーク</span><span class="ww">イベントを</span><span class="ww">共に</span><span class="ww">創り</span><span class="ww">あげ</span><span class="ww">よう!</span>
<span class="ww">JFL</span><span class="ww">×</span><span class="ww">Amadana</span> <span class="ww">Music</span> <span class="ww">オリジナル・</span><span class="ww">ラジオ</span><span class="ww">制作</span><span class="ww">プロジェクト</span>
<span class="ww">ラジオと</span><span class="ww">音楽を</span><span class="ww">愛する</span><span class="ww">人たちに、</span><span class="ww">もっと</span><span class="ww">素敵な</span><span class="ww">空間を。</span><span class="ww">Bluetooth</span><span class="ww">スピーカーとしても</span><span class="ww">使える</span><span class="ww">ラジオを</span><span class="ww">つくろう!</span><span class="ww">もう</span><span class="ww">一</span><span class="ww">つの</span><span class="ww">虚無病。</span><span class="ww">アナザー</span><span class="ww">ストーリー</span> <span class="ww">ピクチャー</span><span class="ww">ブック「</span><span class="ww">nothingness」</span>
<span class="ww">秋田</span><span class="ww">ひろ</span><span class="ww">むが</span><span class="ww">書き下ろした”</span><span class="ww">もう</span><span class="ww">一</span><span class="ww">つの”</span><span class="ww">虚無病</span><span class="ww">ストーリー「</span><span class="ww">nothingness」が</span><span class="ww">制作</span><span class="ww">決定。</span>
<span class="ww">“音楽の</span><span class="ww">街”</span><span class="ww">渋谷の</span><span class="ww">ハロウィンを</span><span class="ww">クリーンに!</span> <span class="ww">シブラジから</span><span class="ww">渋谷を</span><span class="ww">愛する</span><span class="ww">みなさんへ</span>
<span class="ww">地域</span><span class="ww">密着</span><span class="ww">×</span><span class="ww">世界</span><span class="ww">最</span><span class="ww">先端の</span><span class="ww">放送局が</span><span class="ww">賛同する"</span><span class="ww">ハロウィン</span><span class="ww">ごみ</span><span class="ww">ゼロ</span><span class="ww">大</span><span class="ww">作戦</span> <span class="ww">in</span> <span class="ww">渋谷"を</span><span class="ww">ラジオ</span><span class="ww">パーソナリティと</span><span class="ww">一緒に</span><span class="ww">盛り上げ</span><span class="ww">よう</span>
<span class="ww">AIから</span><span class="ww">頑張る</span><span class="ww">ママたちへ。</span><span class="ww">PREMIUM</span><span class="ww">ママ</span><span class="ww">プロジェクト</span><span class="ww">@</span><span class="ww">日本</span><span class="ww">武道館</span>
<span class="ww">全国の</span><span class="ww">ママたちに</span><span class="ww">もっと</span><span class="ww">ライブを</span><span class="ww">楽しんでもらう</span><span class="ww">ため、</span><span class="ww">11/1(</span><span class="ww">火)の</span><span class="ww">武道館</span><span class="ww">公演で、</span><span class="ww">ママも</span><span class="ww">親子も</span><span class="ww">楽しめる</span><span class="ww">エリアを</span><span class="ww">つくりたい!</span>
ちなみに、SPAN になる前段階だと、品詞情報などを含んだ配列になっています。
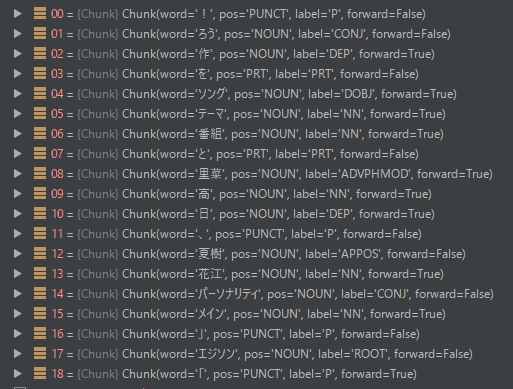
考察
ざっと見た感じ、問題なさそうです。 単語ごとに区切ってありますし、記号(!, 、, ?, etc…) も前の単語にくっついているので違和感はありません。
しかしながら、明らかにおかしかったり、違和感を感じたものもありました。 以下に並べたものは読んでいて「あれ?」となりました。
- 作ろう! -> 作 / ろう!
- 日高里菜と -> 日 / 高 / 里菜と
- 創りあげよう -> 創り / あげ よう
- 最先端 -> 最 / 先端
- もう一つの -> もう / 一 / つの
- 秋田ひろむが -> 秋田 / ひろ / むが
- 11/1(火)の -> 11/1( / 火)
とりわけ致命的なのは、人名を途中で切ってしまっていることです。 API の返り値の時点でこの変な区切りになっていました。 Google 日本語入力はとても人名に強いイメージだったのですが、 Google 自然言語処理API はそんなに強くないみたいです。 これは API の返り値の問題なので、すぐには改善されない可能性が高いです。
また、11/1(火) の括弧が変な区切りになっています。 ソースコードを読んだところ、「記号は直前の単語にくっつける」という Budou 側の処理が原因でした。 こちらについては、今後 Budou がバージョンアップする際に改善されていくのかもしれません。
また、キャッシュが問答無用で実行ディレクトリに作られる上に、 その場所を変更することは出来ません。 これも、今後の機能追加に期待です。
結論
まだ導入するには早い
江藤 光
まだまだ気持ちは新人です。