はじめに
私は主に音楽のサブスクリプションサービスやアラカルトサービスのバックエンド開発兼インフラ領域を担当しています。 今回はRedisからValkeyに移行する際の落とし穴を紹介します。
背景・環境
コスト削減、性能向上を目的としてサービス横断でRedisからValkeyに移行する方針が課されました。
AWS公式サイトやQiitaの記事を見る限り、簡単に移行できダウンタイムも発生しないとのことで、まずは弊社のサービスから対応を進めることにしました。
AWS公式サイトからの引用
ダウンタイムゼロの移行: ElastiCache for Redis OSS の既存ユーザーは、ダウンタイムゼロで ElastiCache for Valkey にすばやく移行できます。
稼働中の環境
- AWS Redis ElastiCache (バージョン7.1)
- RDS
↳ キャッシュが存在しなかった場合、このDBからデータを取得する
実行計画
Valkey移行で万が一異常が起きたケースを想定し、安全かつ段階的な移行パスを選択しました。 具体的には、以下の2ステップで対応することにしました。
- Redis 7.1 → Valkey 7.2
- Valkey 7.2 → Valkey 8
このように一度Valkey 7.2系に留めておくことで、ステップ1の実施後に万が一予期せぬ不具合が発生した場合でも、既存のRedis環境へのロールバックが比較的容易になるよう考慮しました。
これにより、移行作業に伴うリスクを最小限に抑え、安定稼働を最優先する戦略です。
移行中に観測された異常
ステップ1、2ともに移行作業自体はダウンタイムなくスムーズに完了したように見えました。
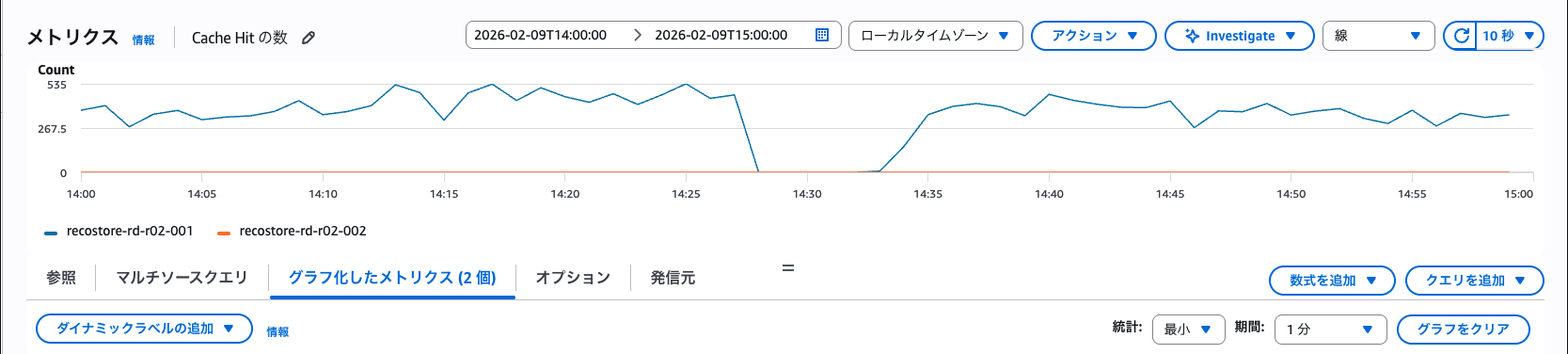
しかし、移行後にCloudWatchのメトリクスを詳細に確認してみると、キャッシュヒット率・キャッシュヒット数ともに途切れている箇所が存在していました。
▼ キャッシュヒット数
▼ キャッシュヒット率
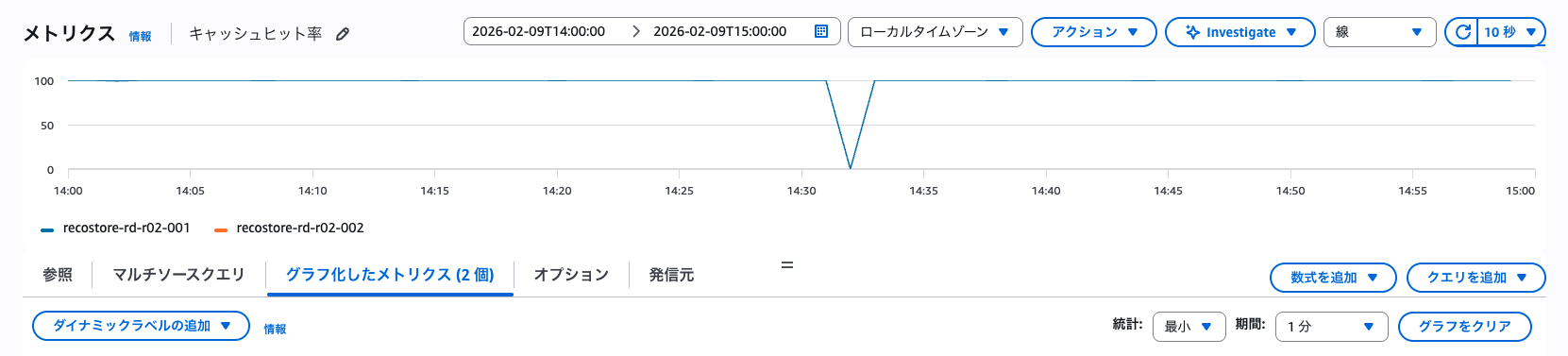
また、キャッシュメトリクスが途切れている時間帯に合わせ、データ取得元であるRDSのCPU使用率が普段よりわずかに上昇していることが確認できました。
「ダウンタイムなく移行可能」と記載されている記事もあり、当初は「移行中、アップデート中にグラフが欠けるのはCloudWatchの仕様なのか?」と推測しました。
しかし、同時にDBへの負荷も増加しているという事実は、「もしかして、ごく短時間ではあるもののダウンタイムが本当に発生しているのでは?」という強い疑問を抱かせました。
この疑問を解消するため、AWSサポートに問い合わせることにしました。
AWSからの公式回答
AWSサポートへの問い合わせに対し、以下の回答をいただきました。
* 移行・バージョンアップ作業において数秒程度の短時間であってもダウンタイムが発生することは、ElastiCacheの標準的な挙動として想定されるものなのか。
結論といたしましては、移行およびバージョンアップの際には、最小限となりますがダウンタイムが発生することが考えられます。
このため、移行やバージョンアップにあたっては、書き込みの受信トラフィックが少ない時間帯での実施や、クライアントが切断された場合の再接続実行などを想定した上でのご対応をご検討いただきたく存じます。
* ダウンタイム自体は発生しないものの、CloudWatchへのメトリクス連携が一時的に停止または遅延し、結果としてグラフ上で低下しているように見える瞬間があるのか
上述しました通り、最小限のダウンタイムが発生することは考えられる事象であることから、その影響を観測されたものと考えられます。端的にまとめると、Valkey移行やバージョンアップにおいては、「最小限のダウンタイムが発生することは想定される事象であり、今回のメトリクス異常はその影響を観測したもの」という結論でした。
考察と所感
「ダウンタイムなし」という情報を鵜呑みにしていた私にとって、この回答は大きな驚きでした。
一般的に「ダウンタイムなし」と表現される場合でも、実際には数秒程度のサービス中断が発生し得るという現実を突きつけられた形です。
この「最小限のダウンタイム」が、弊社のシステムではCloudWatchのメトリクス欠損とDB負荷上昇という形で明確に観測されたわけです。
この経験から、公式ドキュメントや一般的な記事の情報だけでなく、クリティカルなインフラストラクチャの変更においては、より深いレベルでの挙動を理解することの重要性を痛感しました。
特に、データベースやキャッシュといった中核的なサービスに関しては、システム全体への影響を考慮し、最悪のシナリオも想定した上で計画を立てるべきだと改めて認識しました。
まとめ
RedisからValkeyへの移行を通じて、AWS ElastiCacheのバージョンアップや移行作業には「最小限のダウンタイム」が発生し得るという重要な事実を学びました。
これは、一見「ダウンタイムなし」と説明されることが多い中でも、実際の運用においては考慮すべき点です。
今回の経験から得られた教訓と今後の対策は以下の通りです。
- 「最小限のダウンタイム」を許容する設計: キャッシュクライアント側では、接続断を検知した際の再接続ロジックや、キャッシュミス時のフォールバック処理(例:一時的にDBに負荷が集中してもサービスが継続できるか、適切なリトライ処理など)を堅牢に実装することが不可欠。
- 低トラフィック時間帯での実施: 実際のダウンタイムは数秒程度と短いものの、その影響を最小限に抑えるため、サービスへのアクセスが最も少ない時間帯を選んで移行作業を行うべき。
- 多角的なメトリクス監視: キャッシュサービス自体のメトリクスだけでなく、連携するデータベースやアプリケーション層のメトリクスも同時に監視し、より正確な影響範囲とダウンタイムの発生を把握することが重要。
- 公式情報の深掘りと確認: クリティカルな変更を行う際は、公式ドキュメントの記載内容を鵜呑みにせず、不明な点や懸念事項はAWSサポートなどに直接問い合わせて、具体的な挙動を確認する姿勢が大切。
はぜ