AWS re:Invent 2016に参加して思ったことです。
データ分析基盤の最近のトレンドとしては、リアルタイム処理、サーバレス、DataLake(データレイク)、となっているようです。
コンポーネント
コンポーネントとしては、S3、Kinesis、Lambda、DynamoDB、Elasticsearchがメインに利用されていて、特にKinesisでリアルタイム処理を行っている事例が多かったです。 KinesisはFirehoseもStreamもAnalyticsも、どれも多く利用されています。他にもDynamoDB Streamsも利用されています。
DataLake
「DataLake」とは簡単に言うとデータを集める場所という意味です。 DataLakeには、RAWデータの状態で配置し、様々な手段でデータを取得できます。 必要なデータは必要な分だけEMRやRedshiftで処理して、BIツールや連携システムにデータを渡します。
S3
DataLakeはAWS環境ではS3が理想です。 理由は、 ・安価 ・スキーマレス(カラム定義なし) ・データ型に制限なし ・スケールアウト可能 ・データの永続性あり ・耐障害性高い ・セキュリティ設定可能(権限設定、暗号化) ・監査可能 などです。
DataLakeデータ処理フロー
Amazonの資料で、DataLakeとTraditionalな処理の比較図が下記です。
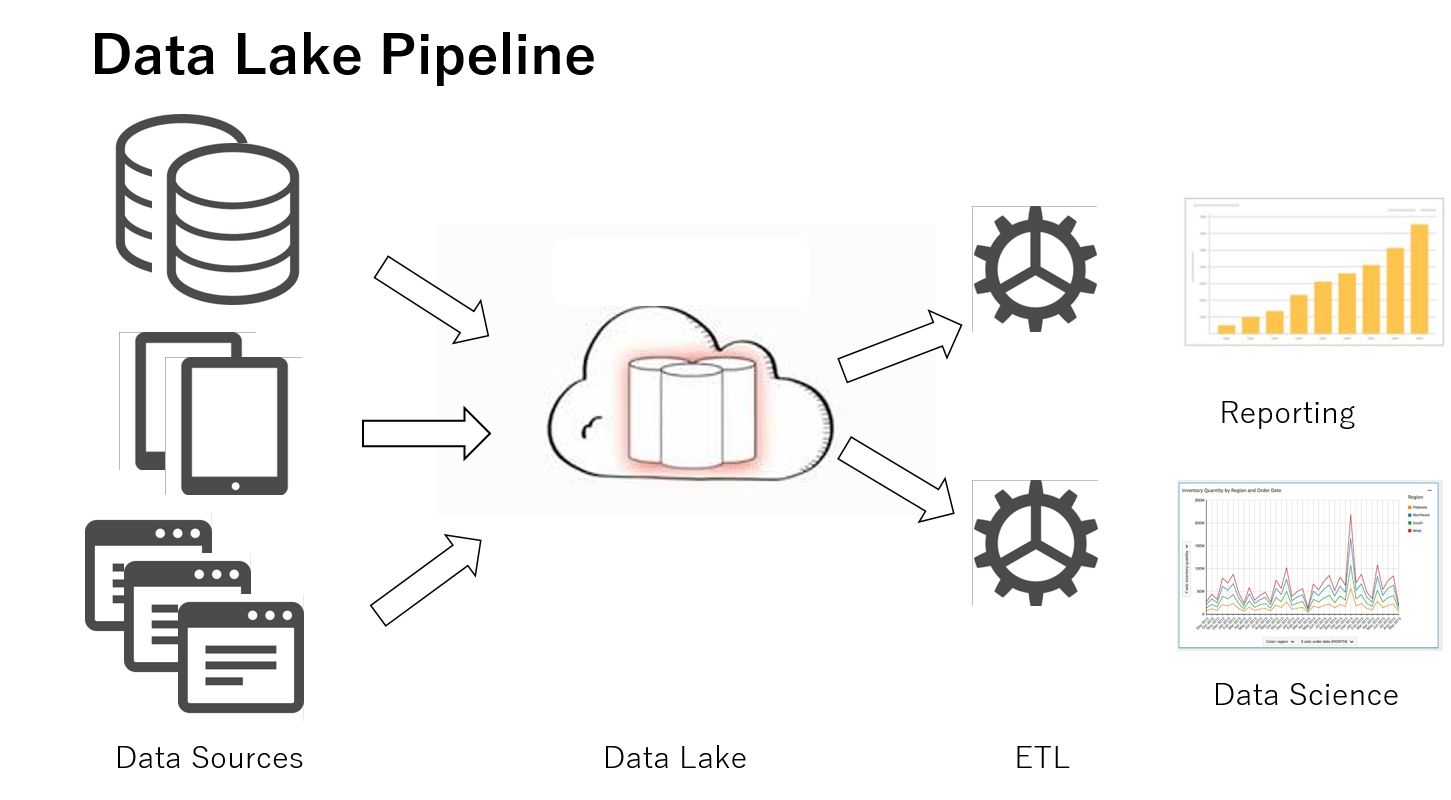

現在のレコチョクのデータ処理フローがまさにTraditionalと呼ばれていました。
まとめ
現状のデータ処理は数年前の設計思想のまま毎日稼働していて、AWSのコンポーネントを有効活用できていません。 コンポーネントを有効活用し、マネージドサービスの利用を増やし運用を楽にしていきたいと思います。
最新情報
新機能「Athena」の発表がありました。S3のファイルに対してSQLを実行できる機能のため、DataLakeに適している機能です。 2016/12現状はUSリージョンでしか利用できません。 https://aws.amazon.com/jp/blogs/news/amazon-athena-interactive-sql-queries-for-data-in-amazon-s3/
Toshiyuki Sato
データをメインに扱っています。



