はじめに
まだ2日目なのにどっと疲れを感じている福治です。 データを分析した際のコードやレポートの管理ってどうすればいいのかを悩んでいたこの頃、そんなさなかにJupyter NotebookをAWS上でサーバレスに使える日がやってきていたのでした。
Jupyter NotebookをAmazon EMR上でサーバレスで
まず、私の場合、Amazon EMRとはなんぞやというところから入りました。 今回の記事を書いたきっかけは、自分自身が今使っているJupyter Notebookが、どのような場面で使われているのかを知りたく、興味を持ったことがきっかけです。
それでは、Amazon EMRとはなんぞやという部分から。
Amazon EMR は、AWS でビッグデータフレームワーク (Apache Hadoop や Apache Spark など) の実行を簡素化して、大量のデータを処理および分析するマネージド型クラスタープラットフォームです。( Amazon EMR とは? より)
つまりは、大量のデータをサーバの台数などをそこまで気にすることなく、処理できるサービスといったところでしょうか。
Amazon EMR上でサーバレスにJupyter Notebookを使える機能は今月19日に出ていたらしいです。ちょうどワークショップが行われていたので、参加してきました!と言いたいのはやまやまですが、一時間近く並んだにもかかわらず、5人ほど前で終了だと言われてしまったので、空いた時間で一人ワークショップを行っていました。(実際のワークショップよりかなり薄い内容になってしまうかもしれませんが、ご了承ください。)
まずは、Amazon EMRでJupyter Notebooksを使う利点から。 (ANT387 – How to Use Jupyter Notebooks with Amazon EMR for Better Productivityより) 簡単に強調されていた部分を思い出しながら、要約すると、以下のような感じでしょうか?
- データサイエンティストの人には、Apache Sparkと使うことで、プロセスの進行具合がわかること。
- AIアドミニストレータの人には、設定や管理が楽であること。
(誤訳があった場合はご了承ください。)

さて、実際にやってみたいと思います。 AWSコンソール上で、Amazon EMRを開いてください。サイドメニューの「Notebooks」を開くと、「ノートブックの作成」とあります。
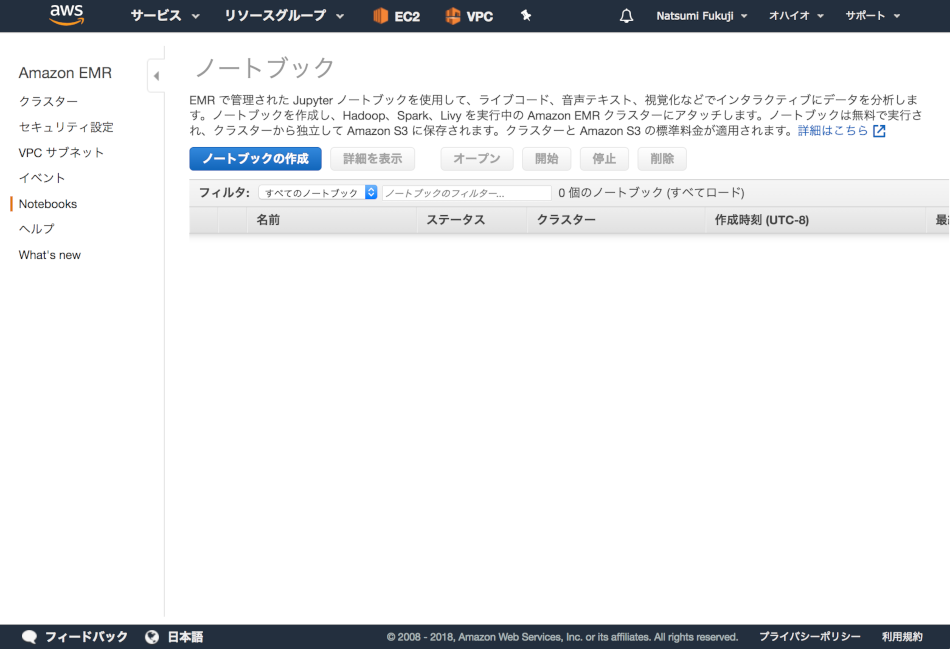
「ノートブックの作成」を押すと、作成の設定画面にいきます。クラスターに関しても、ここで作成することもできます。
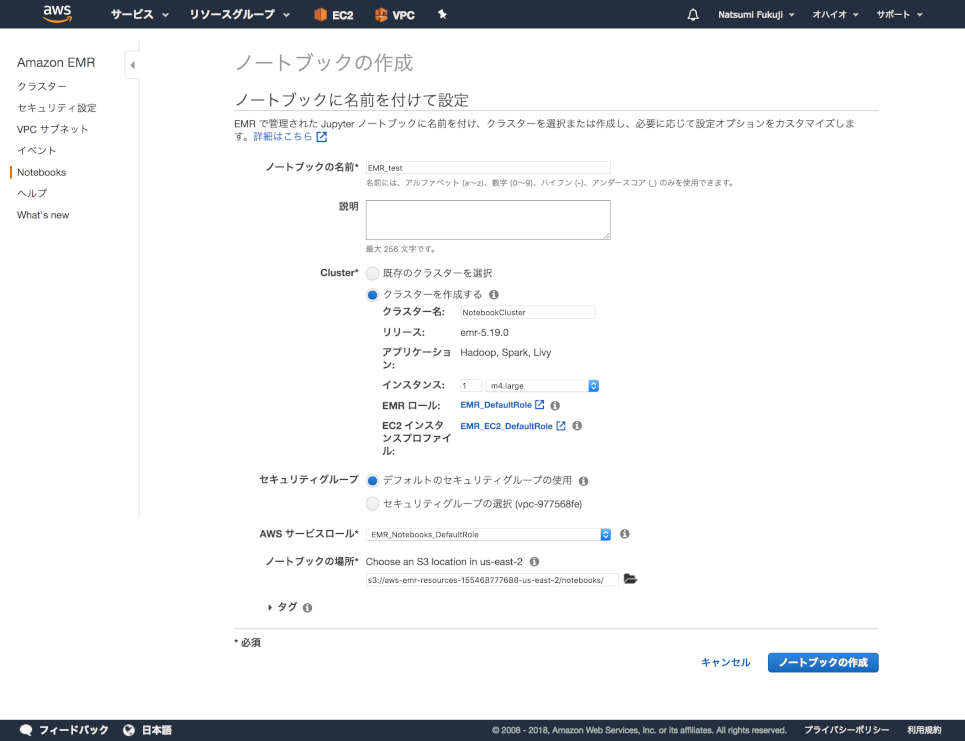
ノートブックの名前とクラスターの選択以外はデフォルトで大丈夫です。 あとは「オープン」のボタンを押せば、使えるようになります!
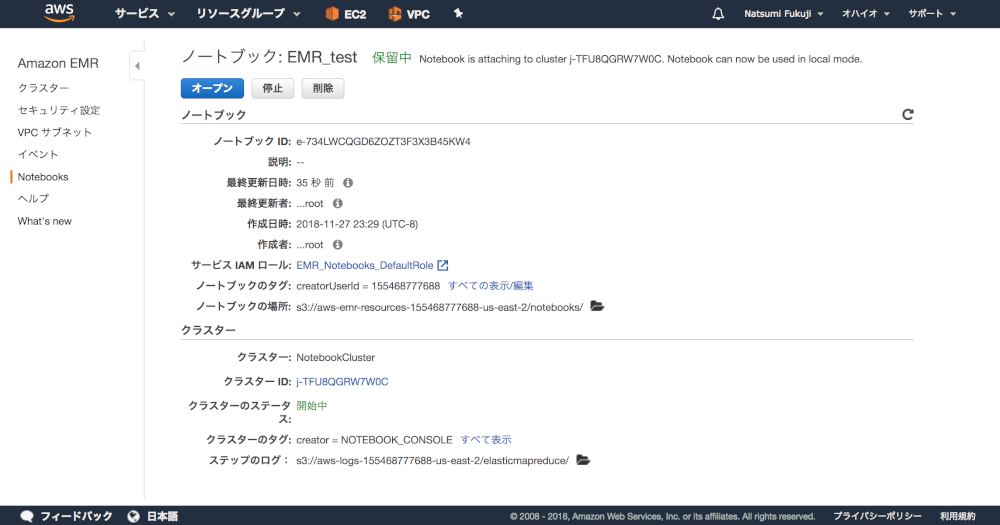
ハマったポイントと感想
今回ハマってしまい、時間がかかったことが2点あります。なぜうまく動かなかったのか、原因の追求まではできていない部分もあるのですが、帰国後にでも、原因追求をしてみたいと思います。
- ホテルのWi-Fiが遅いせいか、簡単な変数宣言でさえ、かなり時間がかかってしまう。普通エラーにならないような命令でさえ、エラーが返される場合がある。(いつもではない。)
- 時間がかかる要因や、原因を調べるために、EMRに入ろうとするもSSHができなかった。 →ノートブック作成前に「キーペアなしで続行」と選択していたら、デフォルトがキーペアなしで続行になってしまう。もし、作成後EMRに入って何かをしたい場合、二進も三進もいかなくなる。
正直、私自身サーバレスに食わず嫌いをしていた部分があるなと思いました。意外と簡単に作ることができて、びっくりしました。ただ、サンドイッチマンの0カロリー理論くらいにまだまだ意味のわからない世界です。
おわりに
はじめてのアメリカ、はじめてのre:Inventはとても楽しいです。
チョークトークで使われるホワイトボードが書いた内容がリアルタイムでスクリーンに映るようになっていたり、移動中に「Superdry極度乾燥(しなさい)」というお店を見つけたり。。。
疲れもありますが、明日からも頑張っていきたいと思います。
福治菜摘美
新米エンジニアです。


