はじめに
こんにちは。 株式会社レコチョクでエンジニアをしている小林です。 普段は、主にPythonを用いたAPIやSolidityによるスマートコントラクトの開発に携わっています。
最近はAIサービスを活用した社内専用のAIチャットツール開発に取り組んでいます。 既にβ版をリリースし、多くの社員にご利用いただいておりますが、更に使い勝手を向上させるため日々機能のアップデートを行っています。
社内専用のチャットツールであるからには、AIへの質問だけでなく社内ドキュメントを簡単に検索できるような機能が欲しいところですが、それらのドキュメントは認証が必要な場所に保管されており、APIからのアクセスは容易ではありません。 何か方法はないかと調べたところ、解決策の1つとしてAmazon Kendraという外部ストレージとの連携が簡単かつ安全に実現できるサービスがありました。 試しにAmazon KendraとSharePointを連携して社内ドキュメントを検索できるかを調査したので、今回はその過程と結果についてまとめたいと思います。
目次
- Amazon Kendraとは
- 簡単なアーキ図と想定フロー
- 事前準備
- SharePointのAPI設定・Amazon KendraのIndex作成
- AWSコンソールで検索テスト
- PythonからKendra APIを実行
- AIと組み合わせる
- さいごに
1. Amazon Kendraとは
Amazon Kendraは、機械学習を活用したドキュメント検索サービスです。 Amazon S3、SharePoint、Google Drive、Slackなど、多様なサービスと連携可能で、これらをデータソースとしてキーワード検索が行えます。 提供したデータや入力情報は学習に利用されないため、社内情報を含むドキュメントも安心してデータソースとして使用できます。
注意事項として、インデックス作成中も利用がない場合でも課金が発生するため、使用しない期間がある場合はインデックスを削除するなどの対策をお勧めします。
2. 簡単なアーキ図と想定フロー
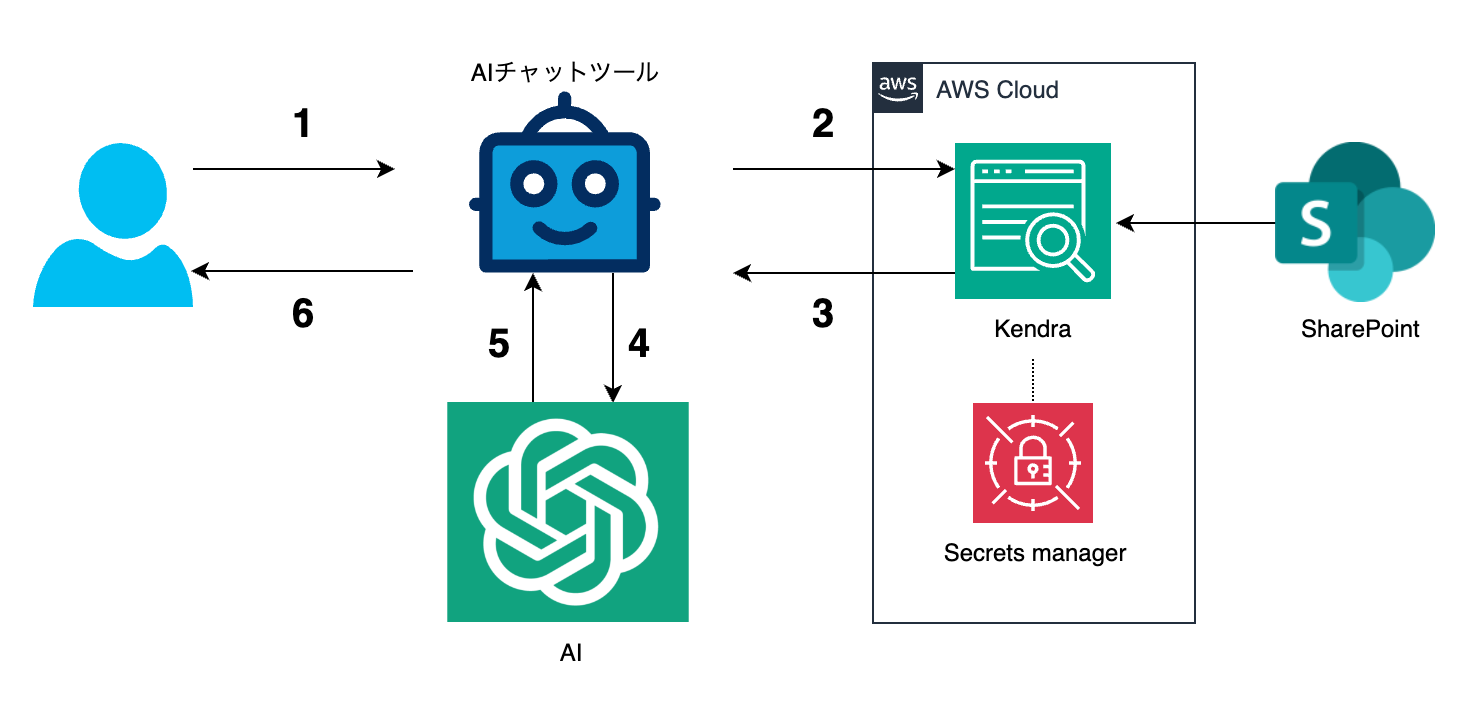
- ユーザーがAIチャットツールにキーワードを入力し送信
- AIチャットツールがKendra APIで上記キーワードを検索
- 検索結果をAIチャットツールに返す
- 検索結果をメッセージとしてAIにリクエストを送信
- AIによるレスポンスをAIチャットツールに返す
- ユーザーにレスポンスを送信
3. 事前準備
Amazon Kendraは特に準備は必要ありませんが、SharePointはいくつか準備が必要です。
Entra IDユーザーの作成
Amazon KendraやSharePointの利用にあたり、MicrosoftのEntra IDユーザーを所有していない場合や検証用のアカウントを利用する場合、こちらを参考にユーザーを作成してください。 作成時に設定するユーザー名とパスワードは後ほど利用しますので控えておいてください。
サイトの作成
SharePointをデータソースとする場合、厳密にはSharePointサイトをデータソースとしているため、サイトが存在しない場合は新規で作成する必要があります。
Microsoftアカウントの権限にもよるかと思いますが、以下の2パターンでのサイト作成が一般的かと思いますのでそれぞれの手順でサイトを作成してください。
手順に従うと、以下のようなサイトが作成されるかと思います。
サイト右上にある 1人のメンバー をクリックして、自分のアカウントもしくはEntra IDユーザーの作成で作成したユーザーが所有者となっていれば完了です。
作成したサイト内に検索したいデータを投入する
サイトを作成したことでAmazon Kendraがデータを検索する場所ができましたが、肝心のデータが存在しないためデータを配置します。
今回はAWSの命名規則に関するMarkdownファイルをデータとして利用します。 ドキュメント/General 配下に AWS 命名規則 というフォルダを作成しそこに入れました。
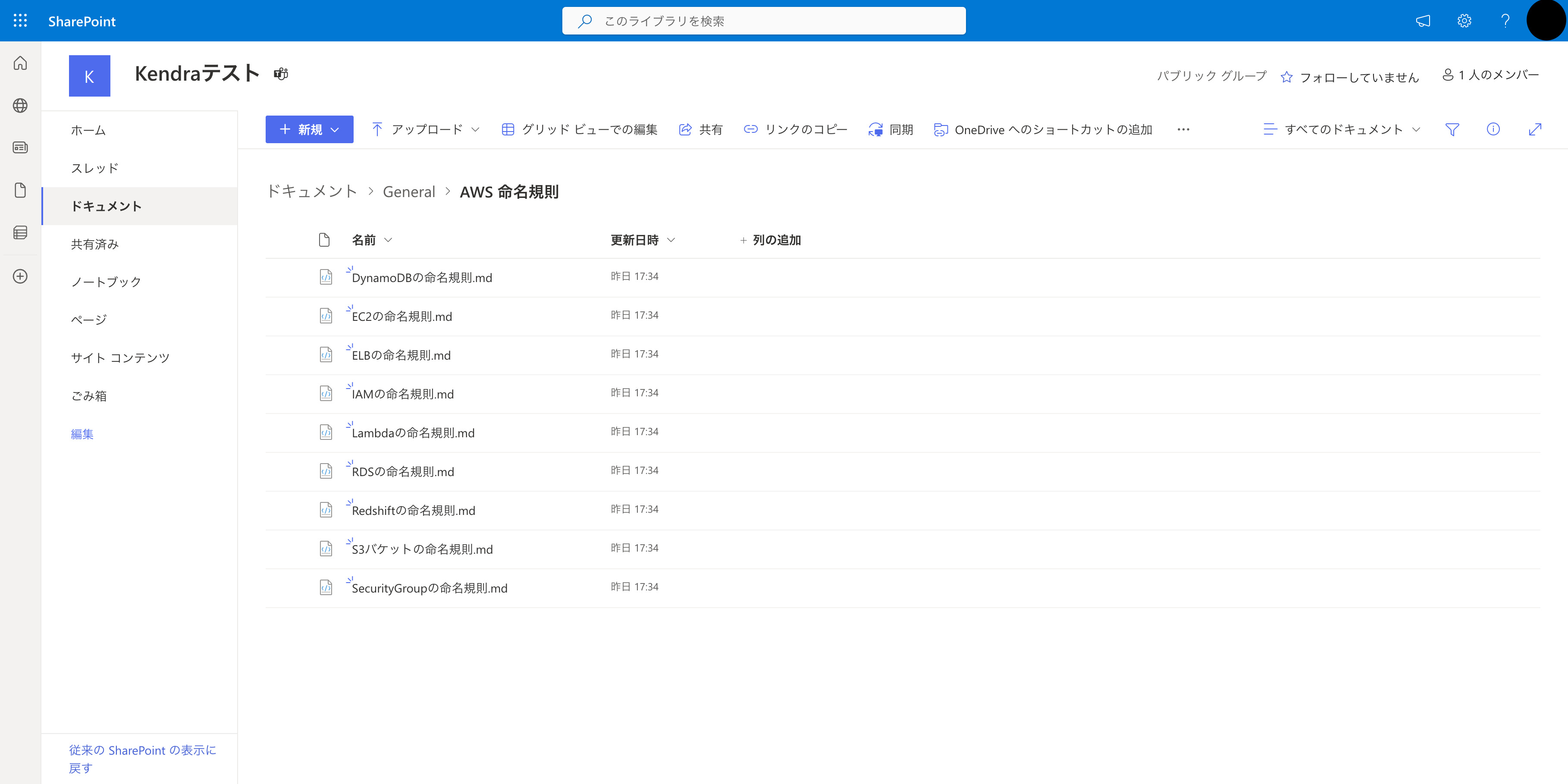
今回検索する S3バケットの命名規則.mdの中身は以下です。
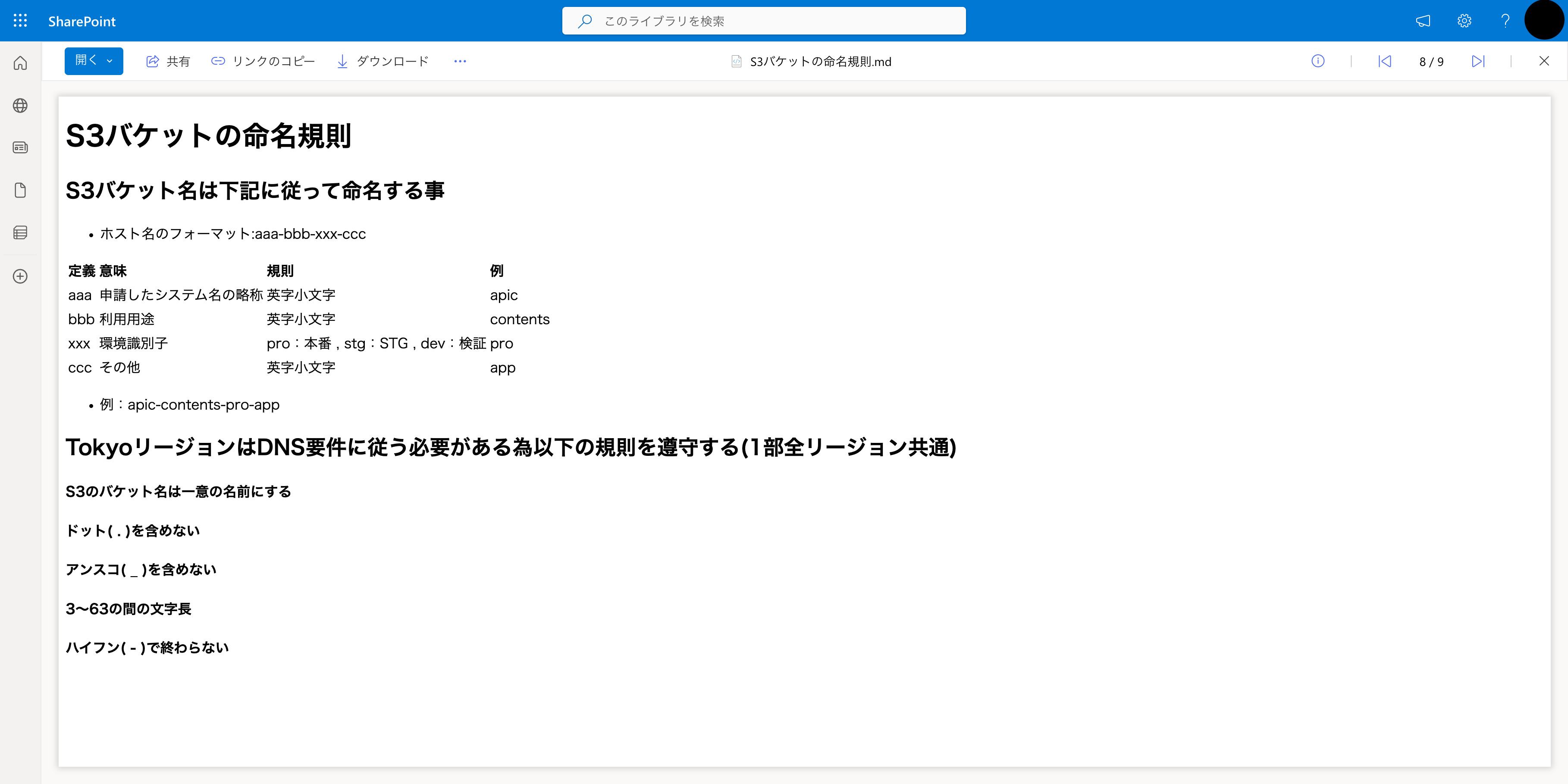
ここまでで事前準備は完了です。 すでに上記のような環境がある方はそちらをご利用いただいて問題ありません。
4. SharePointのAPI設定・Amazon KendraのIndex作成
このセクションでは、SharePointとAmazon Kendraでそれぞれ以下の作業を行います。
SharePoint
Amazon Kendra
これらの作業は、こちらの記事を参考に進めました。 この手順を紹介するとかなり長くなってしまうのでサイトの紹介までとさせていただきます。気になる方や同様の機能を実装したい方はリンクからご確認ください。 基本的にはこの手順通りに設定すれば正常に動作することが確認できています。
注意事項として、サイトに追加したデータによってはIAMポリシーの修正が必要になる場合があるので適宜修正してください。
5. AWSコンソールで検索テスト
Indexの作成とデータソース登録が完了した場合は、以下のような状況になるかと思います。
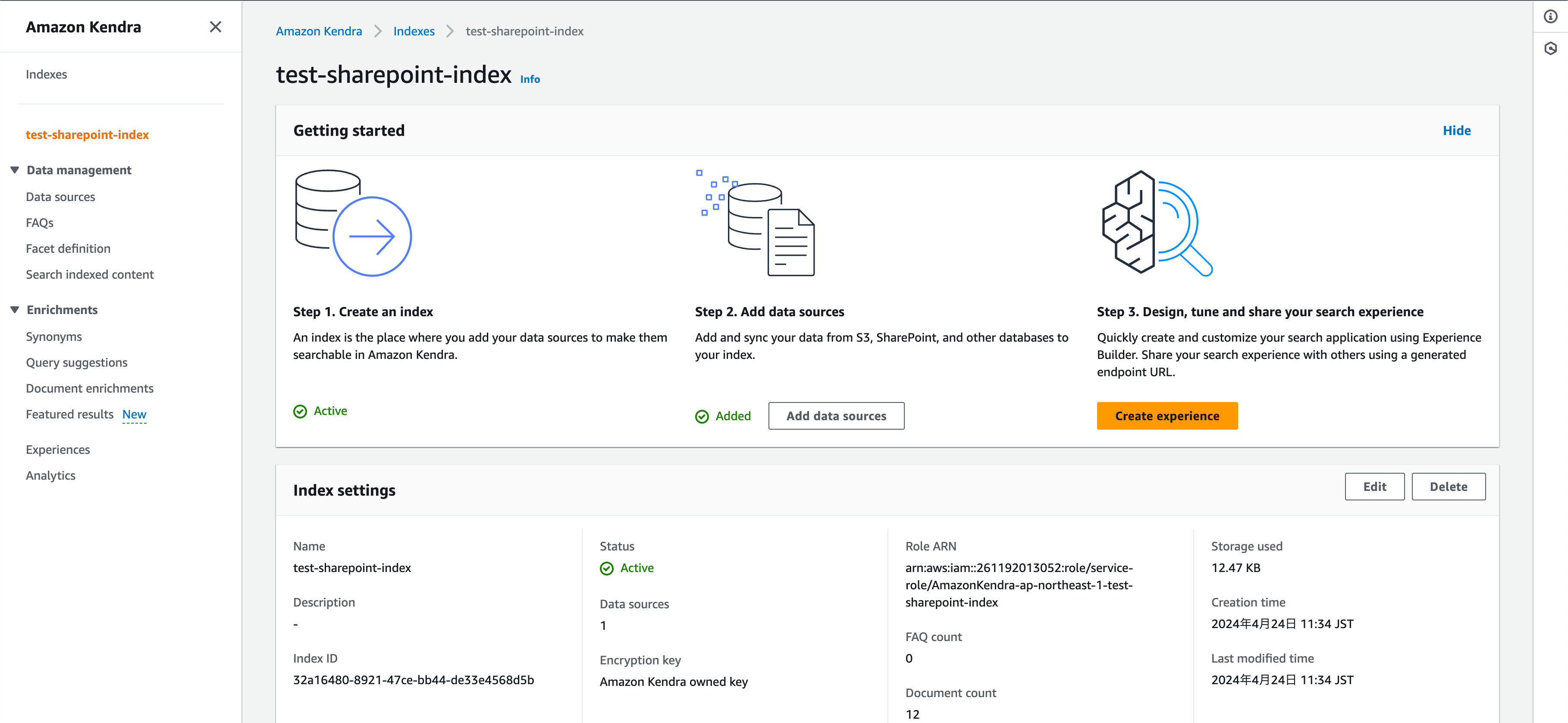
Search indexed contentからAmazon KendraのSearch consoleに移動し、以下のようにSettingsからDefault languageを日本語に変更します。
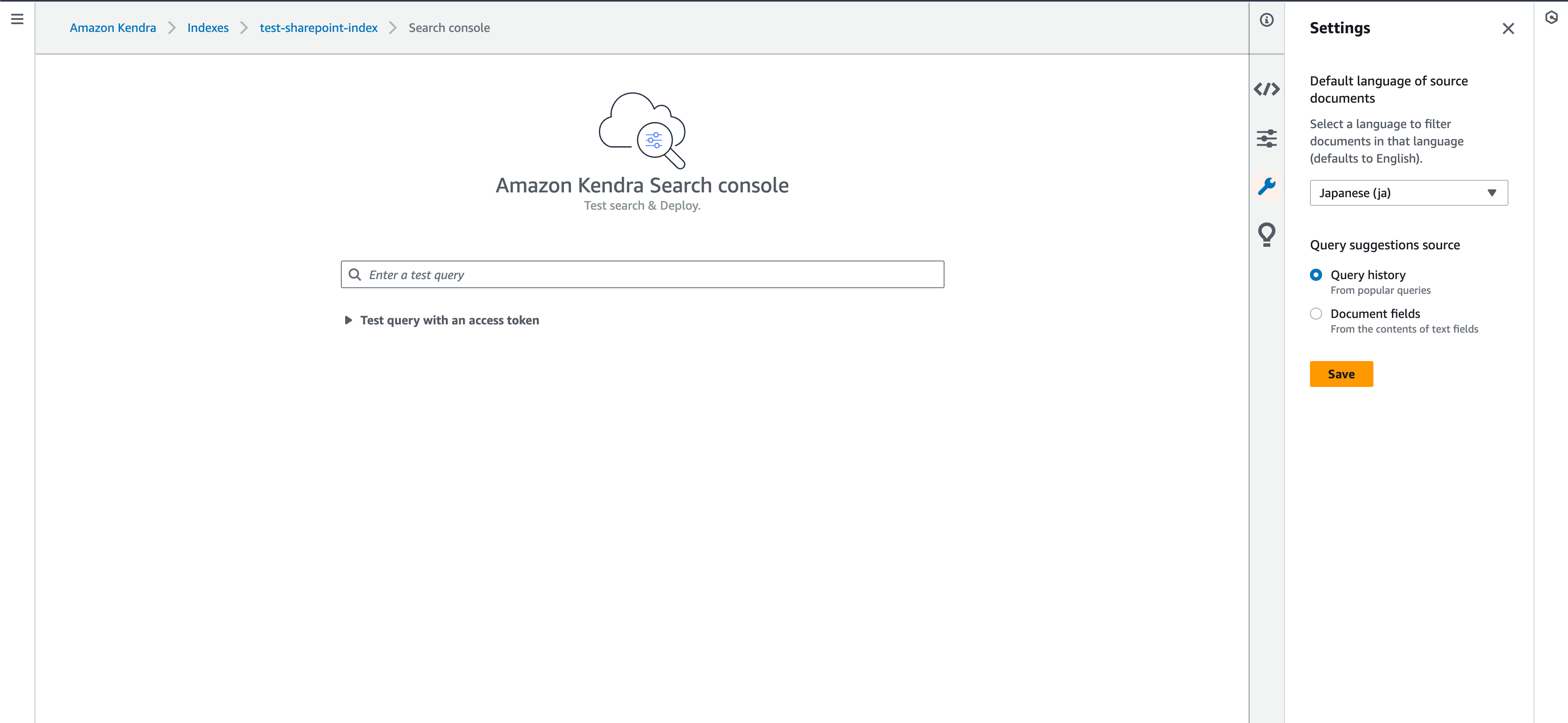
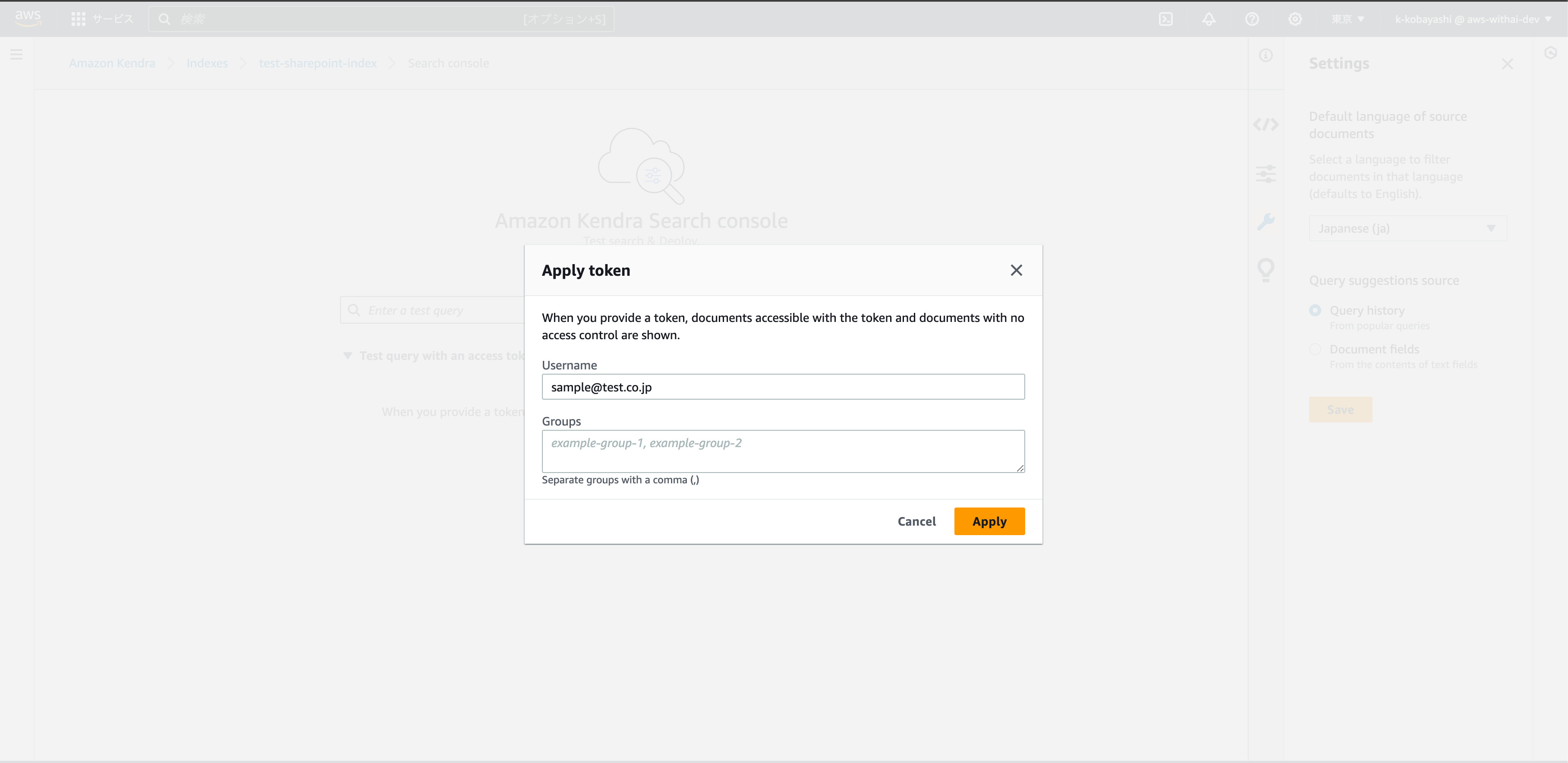
今回の環境ではSharePointへの認証情報としてユーザー情報が必要となるため、以下のようにApply tokenからUsernameに SharePointで利用しているユーザー名を設定します。 私の環境ではメールアドレスでした。
これで検索の準備が完了したため、実際に「S3の命名規則」というキーワードで検索し結果を確認してみます。
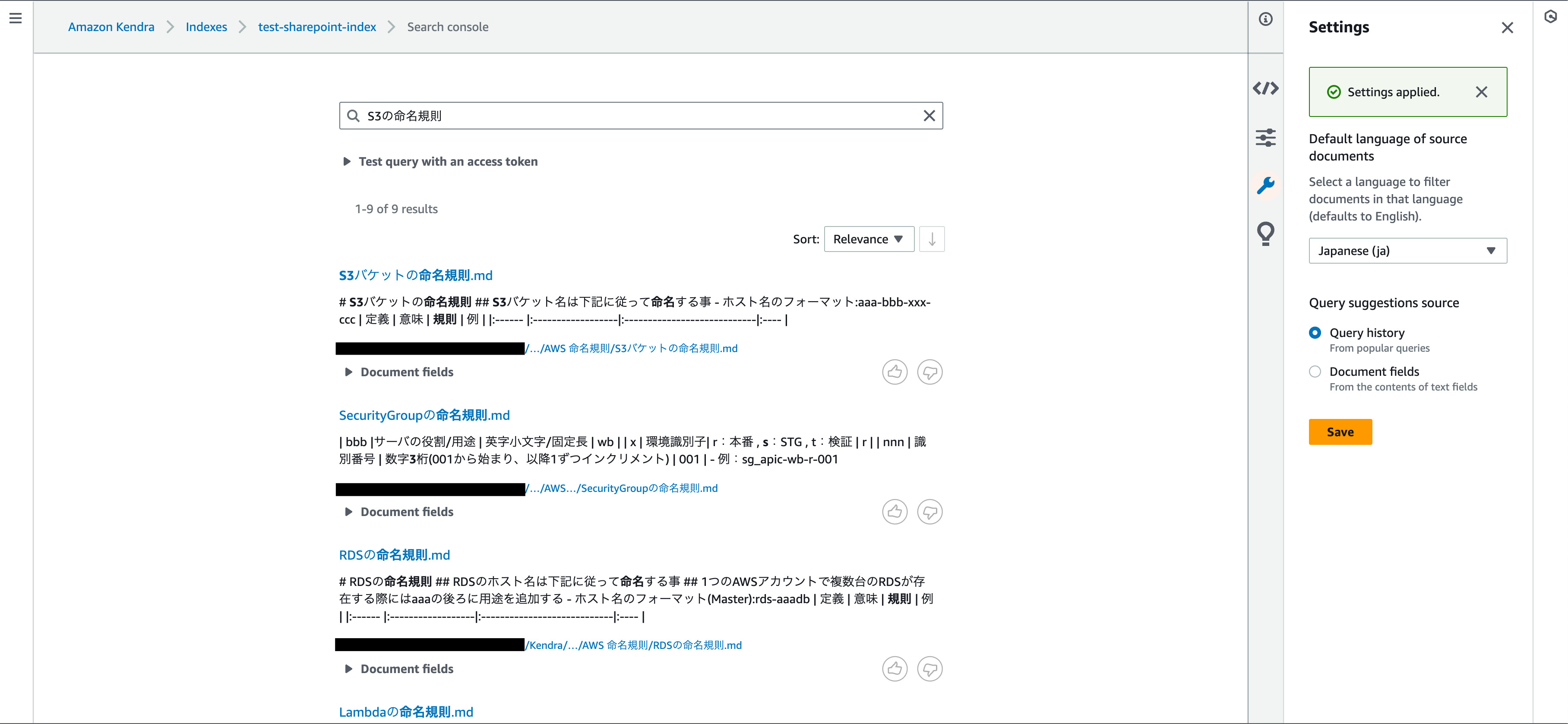
無事に SharePointに追加したMarkdownファイルがヒットしました。
6. PythonからKendra APIを実行
コンソールでAmazon Kendraが期待通りに検索できることを確認できたため、この検索機能をAPIで呼び出せるように実装します。
Kendra Retrieve API
APIの呼び出しは以下のようになります。 公式ドキュメントはこちらです。
kendra = boto3.client('kendra', endpoint_url="https://kendra.ap-northeast-1.amazonaws.com", region_name="ap-northeast-1")
data_str = json.dumps({"username": "sample@test.co.jp"})
response = kendra.retrieve(
QueryText="xxxxxxxxxx",
IndexId="yyyyyyyyyy",
AttributeFilter={
"EqualsTo": {
"Key": "_language_code",
"Value": {"StringValue": "ja"},
},
},
UserContext={
"Token": data_str
},
)
QueryText
- Amazon Kendraで検索するキーワード
IndexId
- 作成したKendraインデックスのID
AttributeFilter
- 検索結果のフィルタリング
- 今回は言語が日本語であるデータをフィルタリングしています
UserContext
- ユーザー情報
- 今回はTokenにstr型でユーザーネームを設定しています
レスポンスはこちらを参考に、以下のようにドキュメントのタイトルと内容を取得するようにします。
search_result = []
for item in response['ResultItems']:
search_result.append(
{
"DocumentTitle": item['DocumentTitle'],
"Content": item['Content'],
}
)
コード全文は以下です。
import boto3
import json
import logging
kendra = boto3.client('kendra', endpoint_url="https://kendra.ap-northeast-1.amazonaws.com", region_name="ap-northeast-1")
try:
data_str = json.dumps({"username": "sample@test.co.jp"})
response = kendra.retrieve(
QueryText="S3の命名規則",
IndexId="xxxxxxxxxx",
AttributeFilter={
"EqualsTo": {
"Key": "_language_code",
"Value": {"StringValue": "ja"},
},
},
UserContext={
"Token": data_str
},
)
except Exception as e:
logger.info(f"-----> Amazon Kendraで検索に失敗しました: {e}")
return InternalServerError(str(e))
search_result = []
for item in response['ResultItems']:
search_result.append(
{
"DocumentTitle": item['DocumentTitle'],
"Content": item['Content'],
}
)
return search_result
このコードでコンソールでの検索と同様に「S3の命名規則」について検索します。 結果は以下のようになりました。
search_result =
[
{
"DocumentTitle": "S3バケットの命名規則.md",
"Content": "# S3バケットの命名規則 ## S3バケット名は下記に従って命名する事 - ホスト名のフォーマット:aaa-bbb-xxx-ccc | 定義 | 意味 | 規則 | 例 | |:------ |:------------------|:----------------------------|:---- | | aaa | 申請したシステム名の略称 | 英字小文字 | apic | | bbb | 利用用途 | 英字小文字 | contents | | xxx | 環境識別子 | pro:本番 , stg:STG , dev:検証 | pro | | ccc | その他 | 英字小文字 | app | - 例:apic-contents-pro-app"
},
{
"DocumentTitle": "Lambdaの命名規則.md",
"Content": "# Lambdaの命名規則 ## Lambdaの関数名は下記に従って命名する事 - クラスタ名のフォーマット:aaa-bbb-xxx | 定義 | 意味 | 規則 | 例 | |:------ |:------------------|:----------------------------|:---- | | aaa | 申請したシステム名の略称 | 英字小文字 | apic | | bbb | 利用用途 | 英字小文字 | s3dataput | | xxx | 環境識別子| pro:本番 , stg:STG , dev:検証 | pro | - 例:apic-s3dataput-pro"
},
{
"DocumentTitle": "SecurityGroupの命名規則.md",
"Content": "| 定義 | 意味 | 規則 | 例 | |:--------|:------------------|:----------------------------|:---- | | aaa | 申請したシステム名の略 | 英字小文字/固定長 | apic | | bbb |サーバの役割/用途 | 英字小文字/固定長 | wb | | x | 環境識別子| r:本番 , s:STG , t:検証 | r | | nnn | 識別番号 | 数字3桁(001から始まり、以降1ずつインクリメント) | 001 | - 例:sg_apic-wb-r-001"
},
{
"DocumentTitle": "ELBの命名規則.md",
"Content": "| 定義 | 意味 | 規則 | 例 | |:------ |:------------------|:-------------------------|:------- | | elb | 固定|英字小文字/固定長 | - | | aaa | 申請したシステム名の略称 | 英字小文字/固定長 | apic | | bbb | 対象ELBに紐付くEC2種別 | 英字小文字/固定長 | wb | | x | 環境識別子 | r:本番 , s:STG , t:検証 | r(本番) | | nnn | 識別番号 | 数字3桁(1AutoscalingGroupに複数ELBが紐付かない場合は001固定) | 001 | - 例:elb-apic-wb-r-001"
},
APIでもコンソールと同様に検索し結果を取得することができました。 ここまでで、Amazon Kendraと SharePointを連携して社内ドキュメントを検索するという検証が一旦完了しました。
7. AIと組み合わせる
検索ができたとはいえ、上記のレスポンスをそのままユーザーに返してはあまりにわかりにくいため、機能追加を見据えてAIにデータをまとめてもらいます。
AIへのリクエスト部分のコードは、これまた非常に長くなるため申し訳ありませんが割愛します。こちらが参考になるかと思いますので、興味がある方はよろしければご確認ください。
以下のように、検索結果からキーワードについての情報をまとめてもらうようにリクエストを送ります。
# key_word = "S3の命名規則"
message = f"次のリストに含まれるデータから、{key_word}に関する情報をまとめてください。 data: {search_result}"
このリクエストに対するAIのレスポンスが以下になります。
S3バケットの命名規則に関する情報は以下の通りです
### S3バケットの命名に用いるフォーマット
- フォーマット: `aaa-bbb-xxx-ccc`
### 各要素の定義と規則
1. **aaa (システム名の略称)**
- 規則: 英字小文字
- 例: apic
2. **bbb (利用用途)**
- 規則: 英字小文字
- 例: contents
3. **xxx (環境識別子)**
- 規則: 環境による識別子
- pro: 本番
- stg: STG
- dev: 検証
- 例: pro
4. **ccc (その他)**
- 規則: 英字小文字
- 例: app
### 全体の例
- **例**: `apic-contents-pro-app`
### 追加の命名規則(TokyoリージョンでのDNS要件など)
- S3のバケット名は一意である必要があります。
- ドット(`.`)やアンダースコア(`_`)を含めず、3〜63文字の長さであること。
- ハイフン(`-`)で名前が終わってはいけません。
以下の元データと比較しても過不足なく、十分にわかりやすい回答になっているかと思います。
8. さいごに
今回は、Amazon Kendraを使ってSharePointとの連携についてご紹介しました。
実際に機能として追加するためには検討しなければならないことが多々ありますが、Amazon Kendraがどのようなサービスか、実際に使えそうなのかについて最低限必要な調査はできたかと思います。
拙い記事ではありましたが、最後まで読んでいただきありがとうございました。
参考
小林圭一朗