はじめに
こんにちは、記事をご覧いただきありがとうございます!
データアーキテクトグループの中小路と申します。 レコチョクでデータサイエンスに関わる業務をしています。
6月のMicrosoft Build Japanで紹介されていたMicrosoft Azureの新サービス「Prompt Flow」が気になっていたところ、7月の初旬にプレビュー版で全ユーザー向けに利用可能となりました。
今回はその「Prompt Flow」について紹介していきたいと思います。 ※ プレビュー版のため今後仕様が変更となる可能性があります。
それでは、どうぞよろしくお願いします。
「Prompt Flow」とは
「Prompt Flow」は大規模言語モデル(LLM)を利用したAIアプリケーションの開発フロー全体を効率化するためのツールです。 独自のUIでフロー図を確認しながら、直感的なコーディング作業が可能となります。
現在はプレビュー版となっており、Azure Machine Learning Studioから利用可能です。
今回は ”ユーザーから与えられた自然言語の入力文(日本語)を英訳する簡単なAIアプリケーションを開発する” というシチュエーションで「Prompt Flow」の各種機能を紹介していきます。
事前準備
アプリケーションの開発に必要な各種セッティングを行っていきます。 以下の作業が必要です。
・Machine Learning Studioのワークスペース作成 ・Connectionsの作成 ・Runtimeの作成
では1つ1つ説明をしていきます。
Machine Learning Studioのワークスペース作成
「Prompt Flow」はMachine Learning Studioで利用可能なサービスのため、Machine Learning Studio内のワークスペースを作成する必要があります。 Machine Learning Studioにアクセスし、 Create workspaceから新しいワークスペースを作成します。

作成が完了したら、左のメニューから「Prompt Flow」の開発画面に移動します。
Connectionsの作成
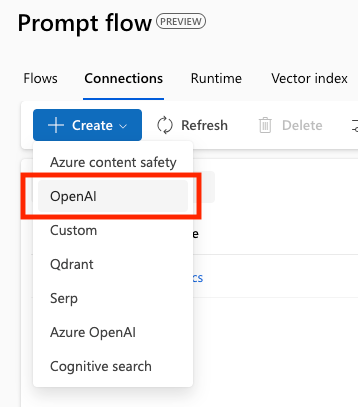
「Prompt Flow」でLLMを利用する際の接続情報を設定しておきます。 Azure OpenAI Serviceで作成したConnectionも使用できますが、今回はOpenAI側のAPIを使用します。 (そのため、プロンプトの実行ごとにOpenAIのAPI利用料金がかかります。)
Connectionsのタブから新規のConnectionを作成します。 今回はOpenAIのAPIを使用するため、メニューから Open AIを選択して、API Keyなど各種情報を入力します。
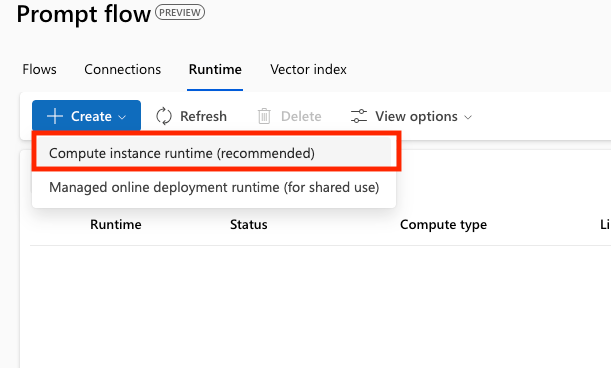
Runtimeの作成
「Prompt Flow」における開発時にアプリケーションを実行する環境を作成します。 作成する環境は Compute instance runtimeとManaged online deployment runtimeの2種類から選択できますが、今回はrecommendされているCompute instance runtimeを選択します。
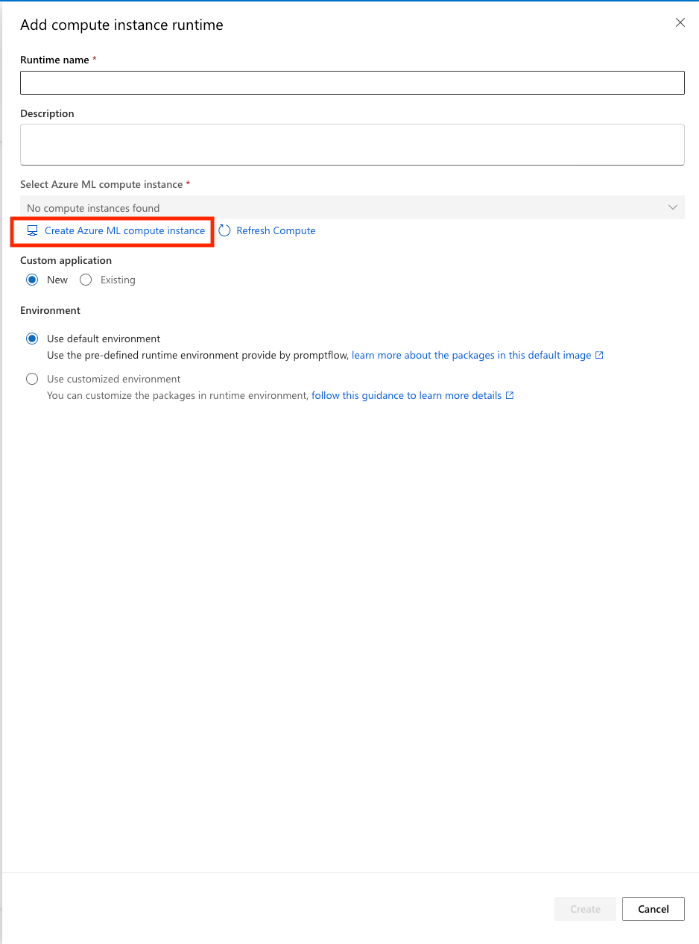
右側に設定のウィザードが表示されます。 まず、VMのインスタンスを作成するため、 Create Azure compute instanceをクリックします。
VMのサイズを選択する設定が表示されますが、今回はVM側で処理を行うことがほとんどないため、一番安い Standard_A1_v2にしておきます。 Select from all optionsを選択すると表示されます。
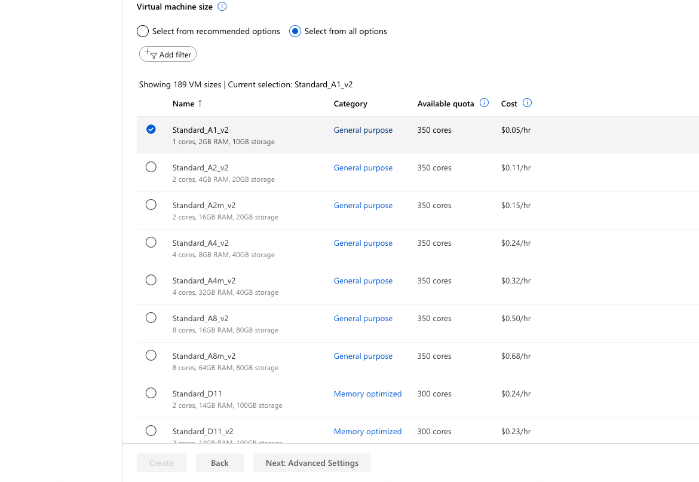
CreateをクリックするとVMインスタンスの作成が開始されます。 10分程度時間がかかるので、待ちます。 ※ 作成されたインスタンスは左側メニューの Computeから管理できます。必要ないときは停止させておくと課金が抑えられます。
作成が完了すると、Select Azure ML compute Instanceで作成したVMインスタンスが指定できるようになります。
Createをクリックし、ランタイムの作成を完了します。
アプリケーション開発
事前準備が完了したので、「Prompt Flow」でアプリケーションを開発していきます。 タブから FlowをクリックしCreateをクリックします。 次に、開発のTypeを指定する必要があります。今回は Standard flowを利用します。

それぞれのTypeには以下の特徴があります。
・Standard flow 標準のフロー ・Chat flow チャットインターフェイスが提供され、1度のチャットで複数回の会話が可能 ・Evaluation flow アプリケーションの評価に特化
では、翻訳アプリケーションの開発に進んでいきます。 まず、サンプルのノードが用意されていますが、必要がないので削除しておきます。
InputsとOutputsのノードは必要ですので残します。
画面右上にRuntimeを指定する設定項目があるので、事前準備で作成したランタイムを設定します。
今回開発する翻訳アプリーケーションですが、以下のような処理で実装しようと思います。
- ユーザーが日本語のテキストを入力 ↓
- 日本語の誤りがないかを校正(LLM) ↓
- 英訳(LLM) ↓
- 翻訳された英文を出力
ユーザーが入力したテキストに誤りがあると正確な英訳ができません。 そこで今回は英訳の前に校正の処理を加えるようにします。
複数のLLMの処理を繋げる場合、LangChainやSemantic Kernelを利用するという手がありますが、「Prompt Flow」を使えば簡単に実装できます。
1の入力処理は Inputsのノードが対応します。 今回は例文として、以下の日本語が入力されたとして、 InputsのValueに設定します。
昔々、あるところにおじいさんとおばいさんが住んでいました。おじいさんは山へしばがりに、おばあさんは家へ洗濯に行きました。おばあさんが川で洗濯をしていると、大きな毛が流てきました。おばあさんはその桃を拾い上げ、家に持ち帰りました。おじいさんとおばあさんが桃を切ろうとした時、中から元気な男の子が飛び出してきました。その子は桃から生まれたので、桃太郎と名付けられました。
桃太郎の冒頭ですが、ところどころに誤りを仕込んでいます。 誤字も複数ありますし、おばあさんが家で洗濯しているのか川で洗濯しているのが謎です。 挙句の果てには桃ではなく毛が流れてきてしまっています。
このような誤った日本語をそのまま英訳をしてしまうと、結果的におかしな英文が出力されてしまいますね。 そのため、前段階で校正の処理を入れることにします。
それでは、2の校正処理を開発します。
上側の項目から +LLMをクリックし以下のように設定します。
・名前: correction ・Connection:事前準備で作成したConnection ・Api: chat ・model: gpt-3.5-turbo ・temperature: 0.3 (出力の多様性を期待していないため低めに設定) ・max_tokens: 1000 ・プロンプト:
system:
あなたは優秀な編集者です。
user:
#以下の文章の校正を実施してください。
{{text}}
・Inputs: Valueの値に ${inputs.text} を設定(Inputsのtextを受け取る)
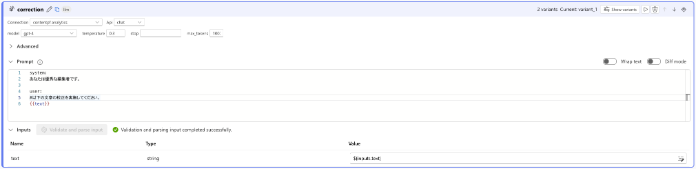
プロンプトは制約条件等指定せず、シンプルにしています。 ▶のマークからこのノード単体で実行することが可能です。 実行結果のアウトプットは >Outputsから確認できます。
アウトプットの中身を確認すると、次のようになっていました。
[1 item
0:{2 items
"system_metrics":{4 items
"completion_tokens":184
"duration":7.212108
"prompt_tokens":227
"total_tokens":411
}
"output":"昔々、あるところにおじいさんとおばあさんが住んでいました。おじいさんは山へしば採りに、おばあさんは家で洗濯をしに行きました。おばあさんが川で洗濯をしていると、大きな桃が流れてきました。おばあさんはその桃を拾い上げ、家に持ち帰りました。おじいさんとおばあさんが桃を切ろうとした時、中から元気な男の子が飛び出してきました。その子は桃から生まれたので、桃太郎と名付けられました。"
}
]
LLMが出力したアウトプットのテキストを確認できる他、処理時間や処理されたトークン数も確認できます。 これによって、処理のパフォーマンスを把握できます。
校正された文章を詳しく確認してみると、おおよそ正しく校正が行われているものの、 ”しば採り”というワードに修正されたり、家・川の洗濯問題が解消されていません。 後者については一見自動校正は難しそうではありますが、家に行ったのに川で洗濯したというシチュエーションはよくわかりませんし、話の流れからしてもおかしいです。 やはり、しっかりと家→川と修正してほしいところです。
そこで、modelをGPT-4に変更することで、正しく校正されるかどうか確認したいと思います。 ここでは「Prompt Flow」の便利機能であるVariantを活用します。
show variantをクリックし、Cloneをクリックします。 そうすると、新たにクローンが”variant_1″という形で作成されます。
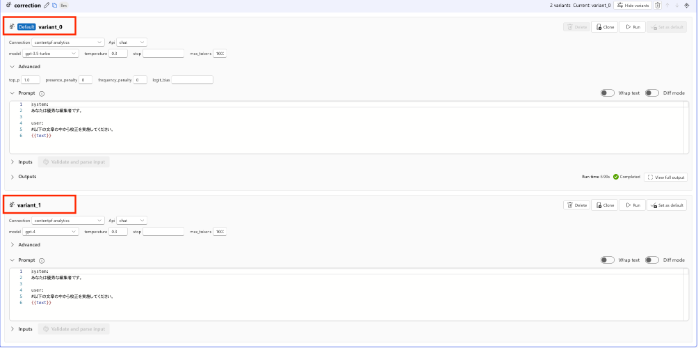
このようにして、Variantを活用することで、単独のノードに対してバージョンを作成し、切り替えが可能になります。 この機能はプロンプトエンジニアリングによって1つのプロンプトを作成する上で、以下のような課題を解決します。
・ベースのプロンプトを変更した際のパフォーマンスの変化を調査したい ・プロンプトの調整がうまく行かなったので、いくつか前に実行したプロンプトに戻りたい ・今まで調整してきたプロンプトを履歴で持ちたい
プロンプトエンジニアリングを行う際、一度のプロンプト作成で上手くいくというケースは稀です。 そのため、何度も調整を繰り返すことになりますが、Variantの機能はその管理を容易にします。
では、新しく追加したvariant_1のモデルをGPT-4に変更し、variant_0とのパフォーマンスを比較します。 アウトプットの中身は以下のようになりました。
[1 item
0:{2 items
"system_metrics":{4 items
"completion_tokens":184
"duration":12.926841
"prompt_tokens":227
"total_tokens":411
}
"output":"昔々、あるところにおじいさんとおばあさんが住んでいました。おじいさんは山へ柴刈りに、おばあさんは川へ洗濯に行きました。おばあさんが川で洗濯をしていると、大きな桃が流れてきました。おばあさんはその桃を拾い上げ、家に持ち帰りました。おじいさんとおばあさんが桃を切ろうとした時、中から元気な男の子が飛び出してきました。その子は桃から生まれたので、桃太郎と名付けられました。"
}
]
variant_1のoutputを確認すると、今回は完璧に校正できていることが分かります。
API利用課金額と校正の精度のトレードオフですが、今回はvariant_1を採用することにします。 variant_1の Set as defaultをクリックし、デフォルトにセットしておきます。
このようにVariantを活用することで、複数のバージョンを比較することができます。 また、今回はボリュームの問題で詳細は紹介しませんが、「Bulk test」という機能を活用することで、フロー全体における、複数の入力に対するVariant別のパフォーマンスを比較できます。
Variantの機能はプロンプトエンジニアリングと非常に相性が良いです。
それでは、次は3の翻訳処理を実装します。
+LLMをクリックし以下のように設定します。
・名前: translation ・Connection:事前準備で作成したConnection ・Api: chat ・model: gpt-3.5-turbo ・temperature: 0.7 ・max_tokens: 1000 ・プロンプト:
system:
あなたは優秀な翻訳家です。
user:
以下の日本語の文章を英訳してください。
{{text}}
・Inputs: Valueの値に ${correction.output} を設定(correctionのtextを受け取る)
詳細は省略しますが、Variantの比較を行い、API利用課金額と校正の精度のトレードオフを検討した結果、gpt-3.5-turboを採用することにしました。
アウトプットは下記のようになりました。
[1 item
0:{2 items
"system_metrics":{4 items
"completion_tokens":108
"duration":4.651284
"prompt_tokens":228
"total_tokens":336
}
"output":"Once upon a time, there lived an old man and an old woman in a certain place. The old man went to cut firewood in the mountains, and the old woman went to the river to do laundry. While the old woman was doing laundry in the river, a large peach came floating by. She picked up the peach and brought it home. When the old man and the old woman tried to cut the peach, a healthy boy jumped out from inside. Since he was born from a peach, he was named Momotaro."
}
]
しっかりと英訳ができていることがわかります。
最後に4の出力処理を実装します。
OutputsのノードのValueに ${translation.output} を設定します。
これですべての処理の実装が完了しました。
アプリケーション実行
画面の右側にはフロー図が自動作成されます。
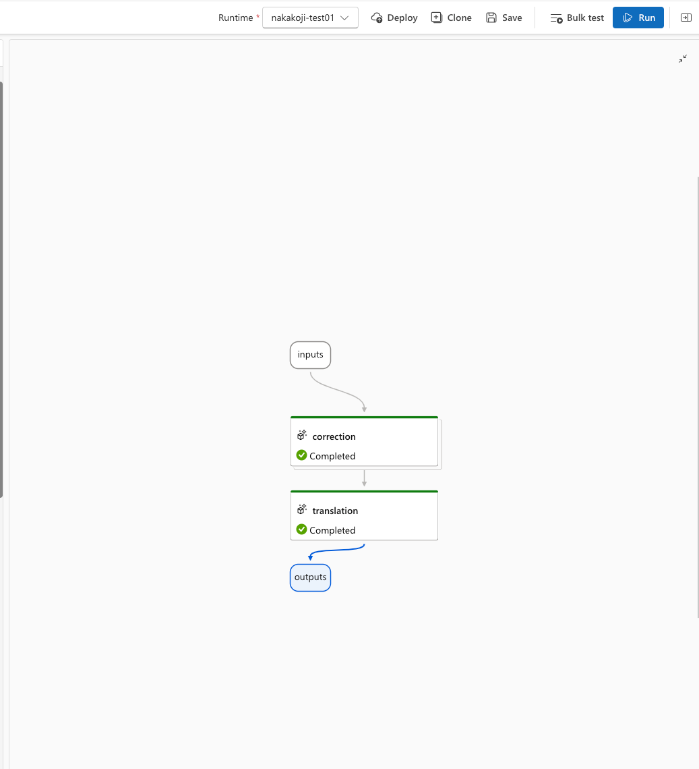
>Runをクリックしフロー全体の処理を実行します。

デフォルトに指定したVariantのみで実行したいので、このウィザードでは、 Use default variant for all nodesを選択します。
画面上部に「Run completed」と表示されれば問題なく処理が完了しています。
また、画面上部の三点リーダーから実行結果を確認できます。 Traceのタブからは、各ノードごとの処理時間を確認できます。 処理時間のボトルネックを特定するのに使えそうです。

開発したアプリケーションは Deployボタンからデプロイすることが可能です。 デプロイの設定では、デプロイ先のVMインスタンスの作成が必要です。 当然課金もされるのでお気を付けください。
左側のメニューの Endpointsから、作成されたエンドポイントの管理が可能です。 ConsumptionタブではRESTエンドポイントのURLやAPIキー、エンドポイントを実行するためのサンプルコードを確認できます。
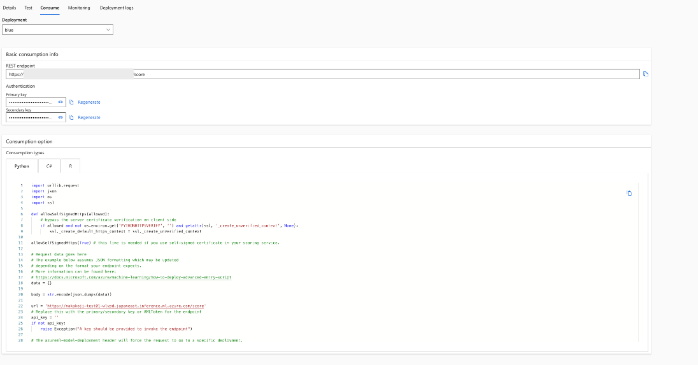
https://blog.tools.product.recochoku.net/wp-content/uploads/2023/07/cf6fc2328addd54697ce9c7f813880c4.png
おわりに
今回は簡単な翻訳アプリーケーションを作成するというシチュエーションで、「Prompt Flow」の使用方法を紹介しました。
「Prompt Flow」はLLMを利用したAIアプリケーション開発を効率化する様々な便利機能が備わっています。 中でもVariantの機能はイチオシで、これを使いこなすことで開発の効率性を大きく向上させることが可能です。
また、ノードにはPythonのコードを追加することもできる他、Cognitive SearchなどのAzureのサービスを呼び出すことも可能なため、非常に自由度の高い開発が可能です。
現在はまだプレビュー版ですので、今後製品版が公開されれば、機能がさらに充実すると想定されます。 引き続き情報をキャッチアップしながら、上手く使いこなし、経験を積んでいきたいと思います。
参考文献
https://learn.microsoft.com/en-us/azure/machine-learning/prompt-flow/get-started-prompt-flow?view=azureml-api-2
中小路裕亮




{kind=link}