はじめに
皆さまご存知の通り、2022 年 11 月に OpenAI が公開した ChatGPT が世界中で話題となっています。 Google も対抗して会話型 AI サービス Bard を発表するなど、にわかに盛り上がりを見せています。
このブームに乗っかり、ヘルプデスクへ日々寄せられる種々の問合せに自動応答するチャットボットを、OpenAI の GPT-3 を利用して作成できないか試作してみることにしました。
しかし、ヘルプデスクの問合せ窓口は Teams のチャネルやチャット、E メールなど多岐に渡り、スクリーンショットによる問合せも多いため、整った文章データを集めることが困難であるという問題に直面しました。 そこで今回は、データが整っているレコチョクの FAQ サイト1をデータセットとして採用し、まずは現在の GPT-3 のポテンシャルを確かめることを主眼としました。 (ヘルプデスクの問合せデータ収集に関するアプローチについては別の機会に書きたいと思います)
今回の試作の結果、残念ながら皆さまにご利用いただくようなシステムの構築には至りませんでした。 本稿では、現時点で構築しているシステムの概要、および課題点を明らかにしていきます。
構成図
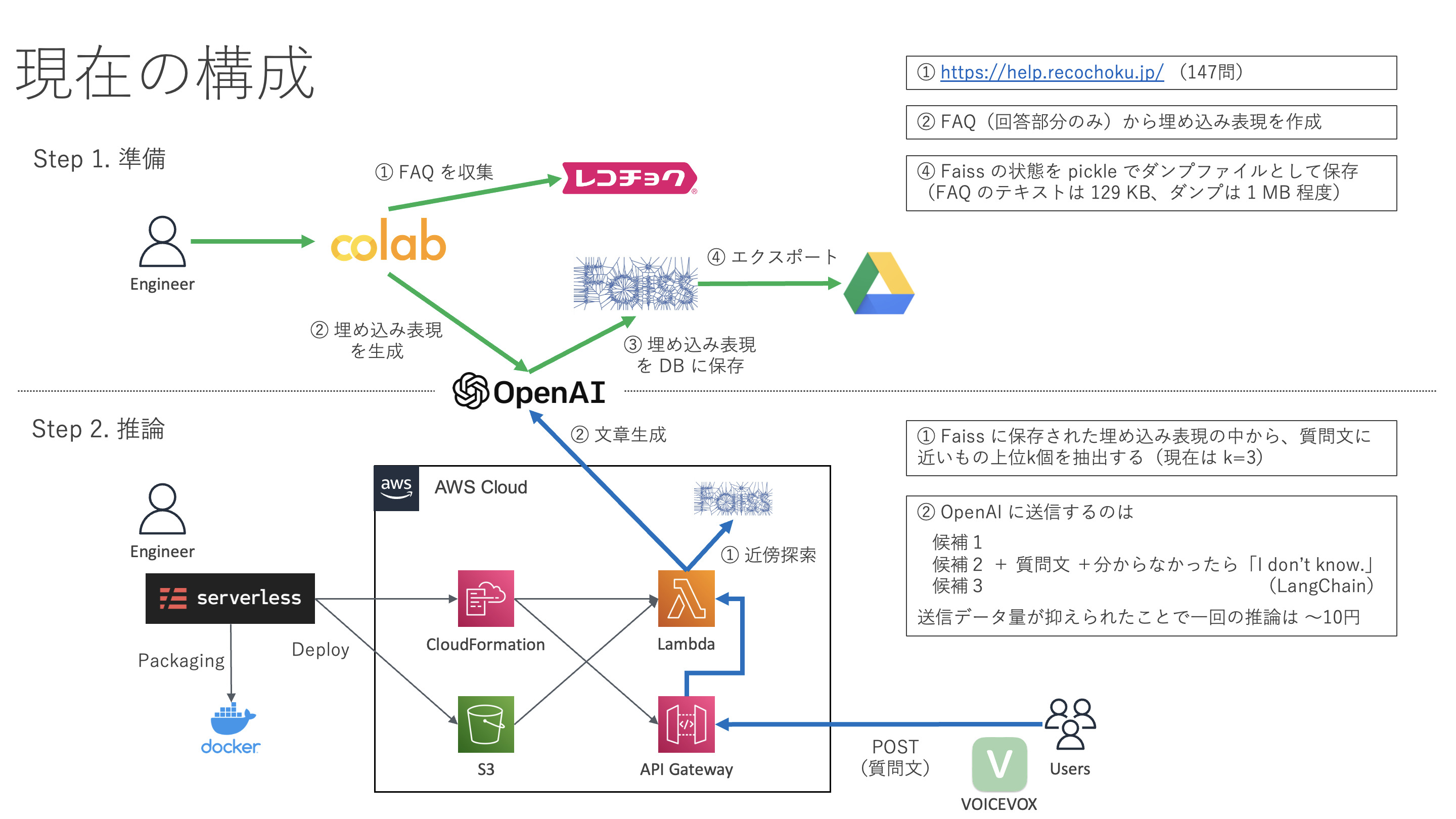
準備
FAQ を収集し、埋め込み表現を生成します。
- レコチョクの FAQ サイトをスクレイピングして FAQ を収集します。 147 問を収集することができました。
OpenAI の API で FAQ(回答部分のみ)の埋め込み表現を生成します。 埋め込み表現は一度 Faiss で保存し、Google Drive にダンプファイルとしてエクスポートします。 FAQ のテキスト 129 KB に対し、エクスポートしたダンプファイルは 1 MB 程度でした。
- preparation.py (アップロードの関係上txtファイルになっています)
推論
ここからは回答を生成する推論フェーズの流れを見ていきます。
GPT-3 はレコチョクの FAQ を学習していないので、いきなり質問すると膨大な知識の中からレコチョクとは無関係な回答を生成します。 皆さんが学生時代に受けた国語のテストのように、「次の文章を読み、後の問いに答えよ」という形式で FAQ の文章も質問文と同時に投げ込むことにより、どこを参照して回答すればよいか明示的に GPT-3 に教えてあげる必要があります。
しかし、処理した文章量に応じて課金される GPT-3 では、推論の度にすべての FAQ の文章を送信するのはコスト面で現実的ではありません。 もう少し絞り込みを行います。
準備段階でダンプファイルとしてエクスポートした FAQ の埋め込み表現があります。 これをインポートしたタイミングで、Faiss による質問文との近傍探索をします。 そうして抽出された上位 3 件の FAQ は、GPT-3 が回答を生成するための情報源の候補としては非常に有力だと考えられます。 これら候補 3 件であれば GPT-3 に送信するのも難しくありません。
3 件の文章と質問文をまとめて GPT-3 に送り、少し待つと回答を得ることができます。 これで推論は完了です。
- requirements.txt
- handler.py (アップロードの関係上txtファイルになっています) (Serverless Framework のサンプルをそのまま使用したので関数名が hello になっています)
デプロイ
以上の推論プログラムを誰でも利用できるようにデプロイします。
今回は(質問文を含む)POST リクエストを API Gateway で受け取り、Lambda 関数を呼び出して推論します。 AWS のすべてのサービスは Serverless Framework を通して CloudFormation で構築しました。 Python ライブラリを含んだ関数のサイズは大きくなるため、Lambda へのデプロイには S3 を経由する必要があります。
- serverless.yml (アップロードの関係上txtファイルになっています)
※ デプロイ前に Docker でパッケージングしている理由 実装に使用した LangChain という Python ライブラリは内部で NumPy を利用しています。 NumPy はC言語で記述されているため、手元の macOS 環境でインストールしたものをパッケージにしてアップロードしても、Linux ベースの Lambda 関数の環境では起動できずエラーとなってしまいます。 そこで Linux ベースのコンテナ内部にインストールし、それをパッケージにしてアップロードするという手順を取っています。
呼び出し
API Gateway のエンドポイントに対してクエリを投げてみます。 回答が得られたら VOICEVOX を利用してかわいい声で読み上げてあげましょう。
- question.py (アップロードの関係上txtファイルになっています)
どのような回答が返ってきたのか、いくつか会話例をピックアップしました。
[質問]: 領収書は発行できますか?
[回答]: 領収書の発行は行っておりません。
[質問]: アルバムスマート購入はいつまで使えます?
[回答]: アルバムスマート購入の利用期限はありません。
[質問]: アルバムスマート購入はいつまで使えます? 英語で
[回答]: There is no expiration date for using Album Smart Purchase.
[質問]: 阪神タイガースは優勝しますか?
[回答]: I don't know.
良かったこと
- GPT-3 の API を実行するだけなので、学習や推論のために高性能なサーバーを準備する必要がない
- GPT-3 に送る FAQ を 3 件まで絞り込んだ結果、1 回の推論の課金を 7〜8 円程度に抑えられている
- FAQ の 3 件の回答を要約した形で回答を生成することもできる
- 質問文に「英語で」と付けておけば GPT-3 が回答をいい感じに英訳してくれる
- 知らないことに関しては「I don’t know.」と言うことができる
課題点
- GPT-3 での推論で想定以上に時間が掛かる
- API Gateway の 30 秒のタイムアウトに間に合わず頻繁にエラーとなってしまう
まとめ
今回はレコチョク FAQ サイトのデータを使って、問合せに回答するチャットボットを試作しました。 推論には時間が掛かるため、現時点では満足できるような性能を得られないことが分かりました。
しかし、この分野の発展は日進月歩であるため、今後も検証を続けていきたいと思います。
参考文献
[1] Build a GitHub support bot with GPT3, LangChain, and Python [2] 無料で使用可能な音声合成ソフトをPythonで喋らせてみた
佐嘉田智之


