AWS AppSync はサーバーレスでサクッと GraphQL を構築することができます。 DynamoDB や RDS、 Lambda といった AWS サービスを簡単にデータソースとして繋ぐことができるのも魅力です。 当然単一のデータソースからデータを取得することもできますが、場合によっては複数データソースをまたいでレスポンスを返したいケースがあります。 そんなときパイプラインリゾルバーを利用すると、複数のデータソースからから順にデータを取得する事ができます。
流れ
DynamoDB のイベントのデータを、RDS のデータと組み合わせて返すことにします。 RDS をデータソースに指定する場合、 Data API が使用できることが条件です。 2024/07/29 現在、利用できるクラスタータイプは以下の3つでした。
- Aurora PostgreSQL プロビジョンドおよび Serverless v2
- Aurora PostgreSQL Serverless v1
- Aurora MySQL Serverless v1
今回は
DBを立ち上げがめんどくさかった 利用できる既存の Aurora MySQL プロビジョンドがあったので、 Lambda をデータソースとして RDS からデータを取得してくる方法にしました。
AppSync → DynamoDB の Eventテーブル → Lambda(RDS の Userテーブル)
みたいな感じです。
実装
API 作成
AWS AppSync で API を作成します。後々作成するのでデータソースは Design from scratch で進めます。
スキーマ作成
シンプルなスキーマです。イベントの ID から紐づく
name と action を返します。
type Event {
id: ID!
name: String!
action: String!
}
type Query {
getEvent(id: String!): Event
}
schema {
query: Query
}
データソースの設定
DynamoDB と Lambda 用のデータソースをそれぞれ作成します。 流れに沿いたいので、一旦 Lambda は空のコードでデプロイします。
ロールについては、今回は簡単なデータ取得しかしないので以下が付与されてればよいかと思います。
DynamoDB
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"dynamodb:GetItem"
],
"Resource": [
"arn:aws:dynamodb:REGION:ACCOUNTNUMBER:table/TABLENAME"
]
}
]
}
Lambda
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"lambda:InvokeFunction"
],
"Resource": [
"arn:aws:lambda:REGION:ACCOUNTNUMBER:function:FUNCTIONNAME"
]
}
]
}
関数の設定
データソースからデータを取得し、返す関数を登録します。
DynamoDB
データソースは先程作成した DynamoDB を選択します。 関数コードは渡された id を元に GetItem するだけの関数です。
import { util } from '@aws-appsync/utils';
export function request(ctx) {
return {
operation: 'GetItem',
key: util.dynamodb.toMapValues({ id: ctx.args.id }),
};
}
export function response(ctx) {
return ctx.result;
}
触っているとわかるかと思いますが、コードサンプルに大体やりたいことのサンプルがあります。 このコードもそのままです。
Lambda
同じく先程作成した Lambda のデータソースを選択します。 今回は Lambda が2番目になるためサンプルコードを少しだけいじる必要があります。
import { util } from '@aws-appsync/utils';
export function request(ctx) {
return {
operation: 'Invoke',
payload: {
result: ctx.prev.result,
},
};
}
export function response(ctx) {
const { result, error } = ctx;
if (error) {
util.error(error.message, error.type, result);
}
return result;
}
Lambda の実装
import json
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
DB_USER = "[user]"
DB_PASSWORD = "[password]"
DB_HOST = "[host]"
DB_NAME = "[db]"
DATABASE_URL = f"mysql+pymysql://{DB_USER}:{DB_PASSWORD}@{DB_HOST}/{DB_NAME}"
engine = create_engine(DATABASE_URL)
Session = sessionmaker(bind=engine)
Base = declarative_base()
class User(Base):
__tablename__ = "user"
id = Column(Integer, primary_key=True)
first_name = Column(String)
last_name = Column(String)
def lambda_handler(event, context):
dynamo_data = event.get("result")
user_id = dynamo_data.get("user_id")
action = dynamo_data.get("action")
session = Session()
try:
result = session.query(User).filter(User.id == user_id).first()
full_name = result.first_name + result.last_name
return {"id": user_id, "name": full_name, "action": action}
except Exception as e:
return {"error": e)}
finally:
session.close()
リゾルバーの設定
定義した getEvent にリゾルバーをアタッチします。 パイプラインリゾルバーを選択し、ランタイムを AppSync JavaScript(APPSYNC_JS)で進めます。 これで getEvent にリゾルバーが紐づきました。 作成したパイプラインから関数を追加することができるので、作成した DynamoDB と Lambda の関数を設定します。
動作の確認
クエリを実行すると
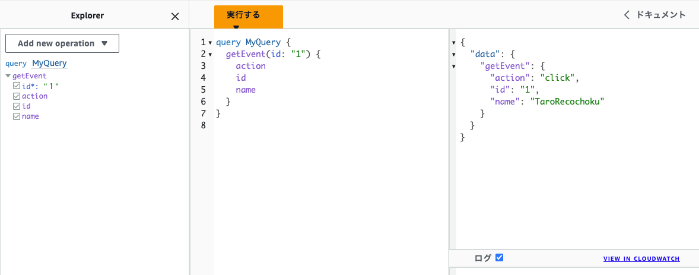
レスポンス確認できました。 今回のように first_name と last_name を組み合わせるくらいの処理や、簡単なビジネスロジックならリゾルバー上でやってしまっても良いのかも(?) なので RDS Data API が利用できるなら、わざわざ Lambda を挟まなくても良さそうです。 AppSync の関数内で複雑なことをするときはログ記録を有効化しておくと良いかもです。ログレベルまで設定しないと INFO レベルが出力されないので注意です(気づかなかった)。
田村航也


