はじめに
「ブラウザはどうやってホームページにアクセスしているのか?」を全4回でまとめました。 今回からはブラウザがホームページの情報を手に入れる流れについて説明していきます。 その2でブラウザがホームページの情報を取得する流れについて説明していきます。
- ネットワークの基礎知識(IPアドレスとドメイン名)
- サーバにデータをリクエストする ← 今回はココ
- サーバのIPアドレスを取得する
- サーバからデータを受け取る
使用した本
ネットワークはなぜつながるのか の内容を基に、自分用のメモとしてまとめました。
URLの解析
インターネット上で情報を入手するためには、まずブラウザにURLを入力する必要があります。 URLにはアクセスしたいファイル名やそのファイルを持っているドメインの情報などが含まれており、ブラウザはそのURLを解析することで目的のファイルを取得します。 下図はURLを解析する際の様子です。
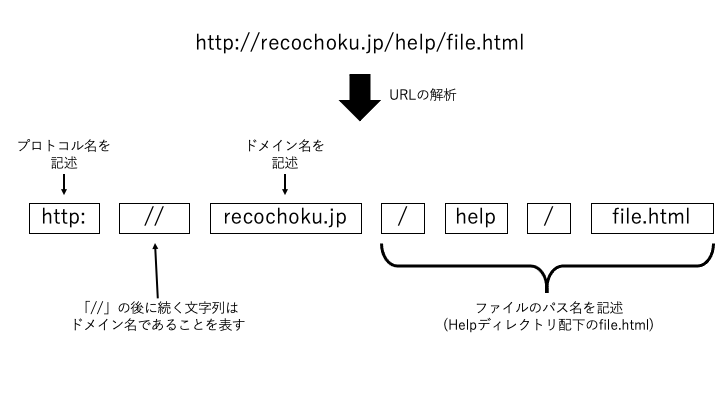
上記の例であれば
recochoku.jpサーバから/help/index.html(helpディレクトリのindex.htmlファイル)を取得するという意味になります。
URLのルール上は
<a href="http://recochoku.jp/special/">http://recochoku.jp/special/</a>のようにファイル名を省略し、ディレクトリ名だけを指定することも可能です。
この場合、サーバ側で「ファイル名が省略された場合、このファイルにアクセスする(一般的にはindex.html)」という設定がされていることが多いため、
自動的に
<a href="http://recochoku.jp/special/index.html">http://recochoku.jp/special/index.html</a>のファイルを取得してくれます。
HTTPプロトコル
URLを解析することで、どのファイルをどのドメインにリクエストすれば良いのかがわかりました。 次に、ブラウザはサーバに対してデータがほしいという旨を伝えるリクエストメッセージを作成します。 ここで作成されるリクエストメッセージはHTTPプロトコルに準拠している必要があります。
HTTPプロトコルとは、クライアントとサーバがやりとりするメッセージの内容や手順について定められたルールのことです。 リクエストメッセージとレスポンスメッセージの書き方は、HTTPプロトコルにルールとして定められています。
リクエストメッセージ
リクエストメッセージのフォーマットは下記のようになっています。

メソッド
- Webサーバにどのような処理をしてほしいのかを記述する。
- e.g.) GET / POST / HEAD etc.
URI
- Webサーバに何を処理してほしいのか(一般的には処理したい/閲覧したいファイル名)を記述する。
- 1リクエストに対して1URIしか記述できない。
HTTPバージョン
- どのバージョンのHTTPプロトコルを準拠しているかを記述する。
メッセージヘッダ
- リクエストに対して付加情報を記述したい際にはここに記述する。
メッセージボディ
- メッセージの本文はここに記述する。
- e.g.) Postの時
q=test&submitSearch=%E6%A4%9C%E7%B4%A2
レスポンスメッセージ
レスポンス・メッセージのフォーマットは下記のようになっています。

HTTPバージョン
- どのバージョンのHTTPプロトコルを準拠しているかを記述する。
ステータスコード
- HTTPリクエストが正常に処理されたのかどうかを示す数字。
- ステータスコードは5つに分類される。
- 情報レスポンス (100–199)
- Webサーバに投げた情報が不足していたり、処理に時間がかかっているときに返却するステータスコード。
- 成功レスポンス (200–299)
- 処理が成功して正常にレスポンスを返すことができた時に返却するステータスコード。
- リダイレクト (300–399)
- リダイレクトを行ったときに返却するステータスコード。
- クライアントエラー (400–499)
- データが存在しない時や、データを見る権限がない時のように、ユーザ側のリクエストに問題があるときに返却するステータスコード。
- サーバエラー (500–599)
- サーバ側に問題があり、正常なリクエストが返せない場合に返却するステータスコード。
- 情報レスポンス (100–199)
レスポンスフレーズ
- ステータスコードをよりわかりやすく文章にしたもの。
メッセージヘッダ
- レスポンスに対して付加情報を記述したい際にはここに記述する。
メッセージボディ
- メッセージの本文はここに記述する。
- e.g.) Postの時
q=test&submitSearch=%E6%A4%9C%E7%B4%A2
ページが取得されるまで
リクエストメッセージについて説明しましたが、リクエストに記述できるURIはひとつだけというルールがあります。 そのため、1回のリクエストで取得できるのは1ファイルだけです。 画像を含むホームページなどは1度のリクエストでは取得できないため、複数回リクエストメッセージが送信されます。
そのため、以下のようなフローを通して処理が実行されます。
- ホームページのHTMLファイルを取得
- 取得したHTMLファイルに書かれている画像ファイルを取得する
- 取得してきた画像ファイルをレイアウトする
という流れで処理が進んでいくため、3枚画像が含まれているホームページを読み込む場合は計4回のリクエストが発生します。
まとめ
- URLから目的のデータと、そのデータを持っているサーバ情報が取得できる。
- サーバにデータをリクエストするときはHTTPプロトコルに準拠したリクエストメッセージを作成する。
- 一度のリクエストメッセージで取得できるデータは1つだけ。
早瀬 大智



