こんにちは、株式会社レコチョク新卒1年目エンジニアの笹野です。 サーバーサイドエンジニアとして、主にdヒッツというサービスに携わっています。
はじめに
みなさん、2023年はどんな曲を聴きましたか?
私はプライベートで2023年に聴いた曲をDBに保存していたので、そのデータをChatGPTに読み込んでもらい、2023年に聴いた音楽を振り返ってみました。そして、振り返りを通してChatGPTがデータ分析に活用できそうか見ていこうと思います。
前提
私は音楽を聴く=
favs4appというプレイリストを再生するという習慣があります。そして、favs4appにある曲を記録するAPIを毎日動かし、DBにその日に聴いた曲を保存しています。今回はそのDBにある2023年のデータをCSVファイルに落とし、それをChatGPTに読み込んでもらいます。
参考までに、2024年2月24日のデータは以下のように記録されています。
date,title,artist,album
2024-02-24,スーパー愛したい,Neguse,スペースシャトルで君の家まで
2024-02-24,Dropkick,&TEAM,First Howling : NOW
2024-02-24,わたしの一番かわいいところ,FRUITS ZIPPER,わたしの一番かわいいところ
2024-02-24,君の可愛いがバレませんように,NIKUCHOMORANMA,君の可愛いがバレませんように
2024-02-24,FREEDOM,Takanori Nishikawa,FREEDOM
2024-02-24,39 (feat. 初音ミク),sasakure.UK,39 (feat. 初音ミク)
2024-02-24,Calc.,Kashitaro Ito,Ichii Senshin
2024-02-24,Highway,Smiler,Melody Line(s)
(最近、懐かしのボカロ曲が再燃しています…!) 聴かなくなった曲はプレイリストから削除しているので、本当にその日に聴いていた曲のみが残っているプレイリストになります。
細かい環境については以下の通りです。
- 環境
- ChatGPT4
- DBはPostgreSQL
日本語でシンプルなDB問い合わせ
まずは用意したCSVファイルを読み込ませて簡単な問い合わせをし、正確な答えが返ってくるかどうか試してみます。
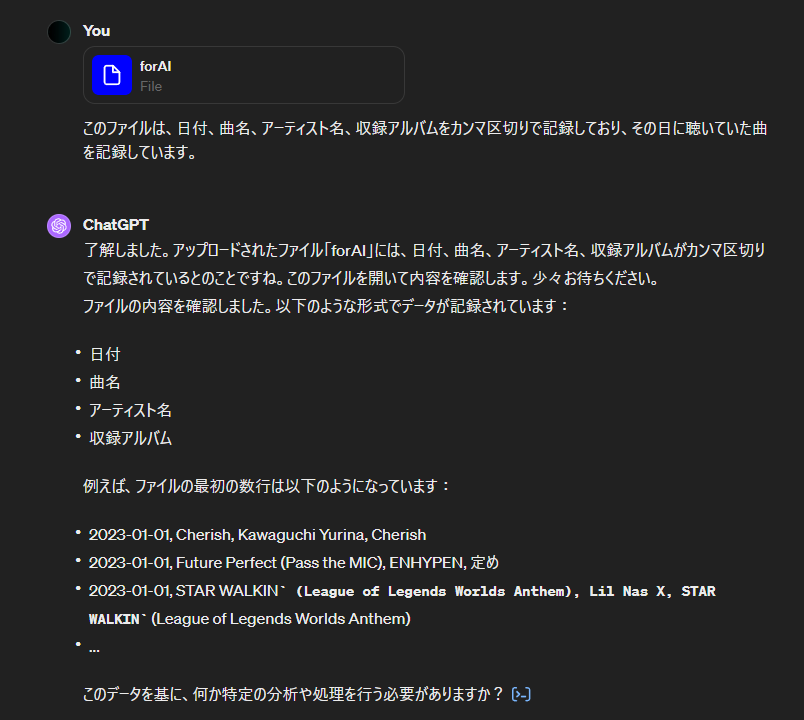
(自分の日本語が若干怪しいですが…)渡したCSVファイルは正しく認識してくれていそうです。
まずはシンプルにどの曲がよく聴かれたのか問い合わせてみます。

ぱっと見は悪くなさそうに感じます。ちなみに、ここで出た回数はその曲を聴いた日数になります。1位の曲は112日で約4ヶ月間も聴いたことになります(驚き) 次は実際のDBでSQLを叩いた結果と比較して、どこまで正確にデータを認識しているのか確認します。 実行したSQL文
SELECT title, artist, count(*)
FROM songs
WHERE extract(YEAR FROM date) = 2023
GROUP BY 1, 2
ORDER BY 3 DESC;
実行結果の一部
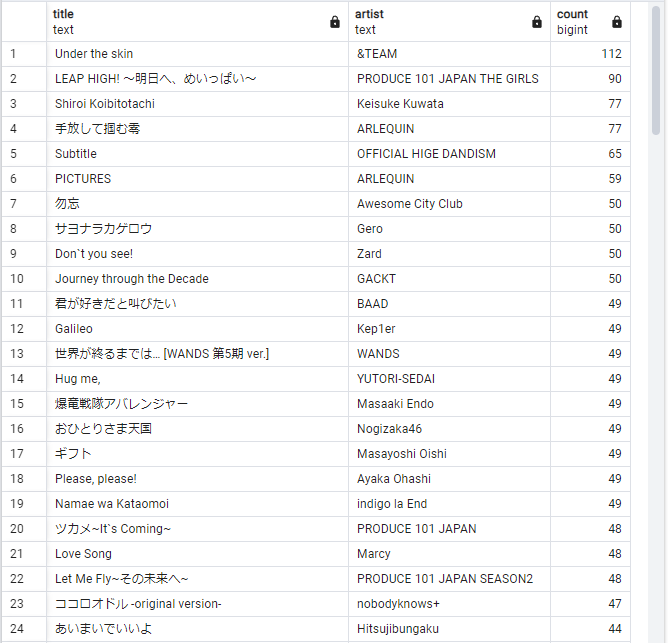
比較した結果、順位もカウント数(その曲を聴いた日数)も全く同じで正確な答えが返ってきました。
私の生成AIの経験だと、データを渡してもすべて見てくれた上での答えが返ってこず、認識に抜け漏れがあるイメージだったので、この時点で意外に感じました。ChatGPTをデータ分析に活用できそうだと思いました。
そして、せっかくなので2023年に聴いたアーティストランキングも問い合わせてみます。
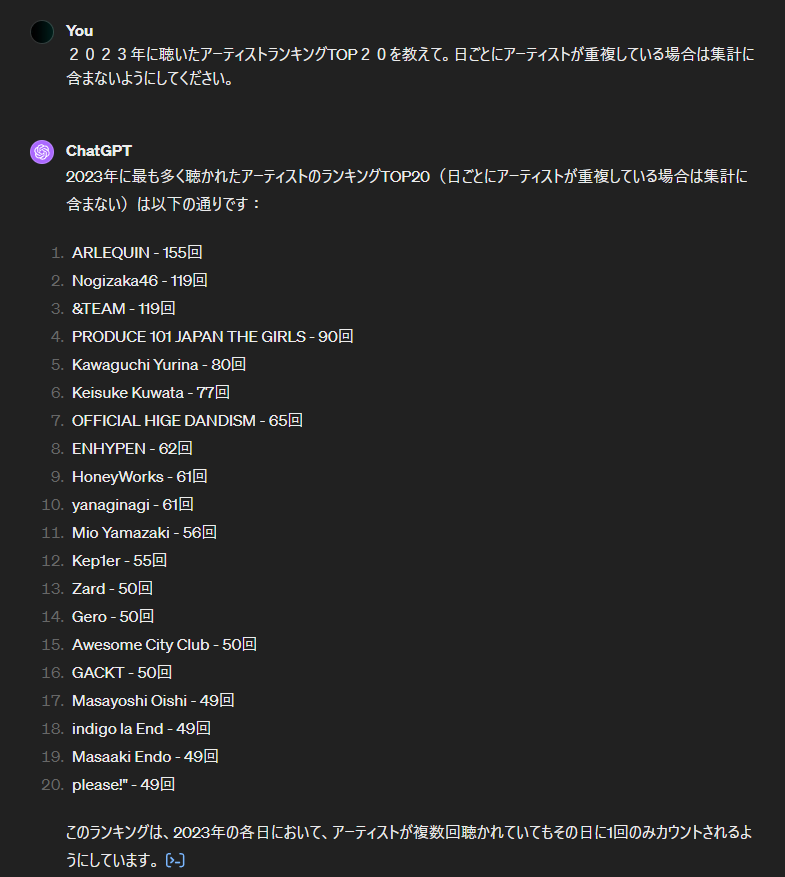
ここに来て20位に
please!” と怪しい文字列が出てきました。CSVあるあるの文字列中にカンマがあるとそこで区切ってしまう問題が発生しているみたいです。
問題のデータ例は以下です。
2023-09-26,"Hug me,",YUTORI-SEDAI,"Hug me,"
2023-09-26,"Please, please!",Ayaka Ohashi,"Please, please!"
このようにカンマを含む文字列についてはダブルクォーテーションで囲まれるようになっているので、そのことをAIに教えてあげます。
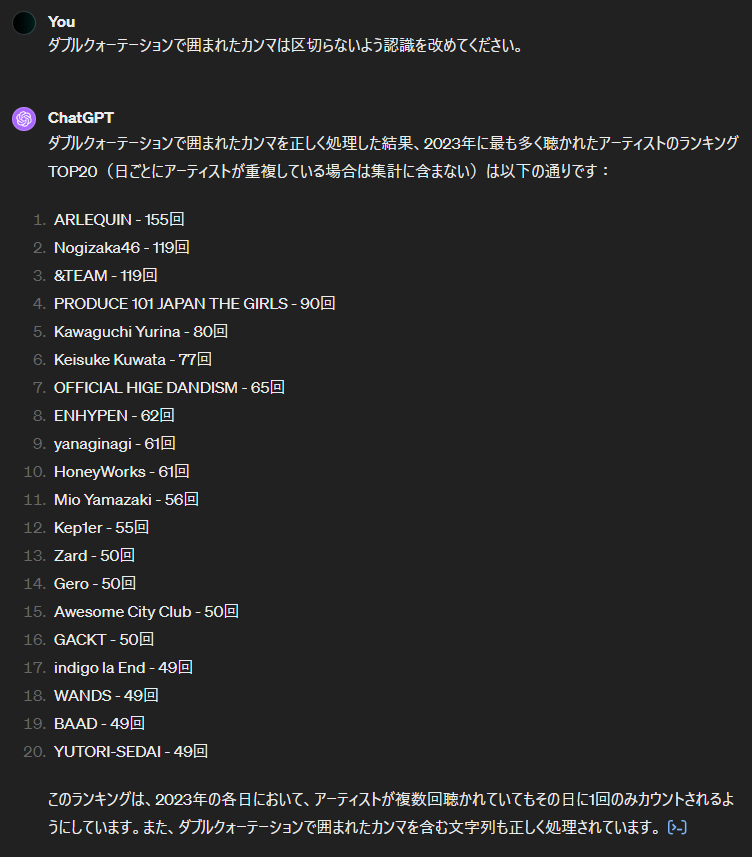
上手くいってそうですね!念のため
please!” の認識が改められているか確認します。Ayaka Ohashiと表示されればOKな内容になります。
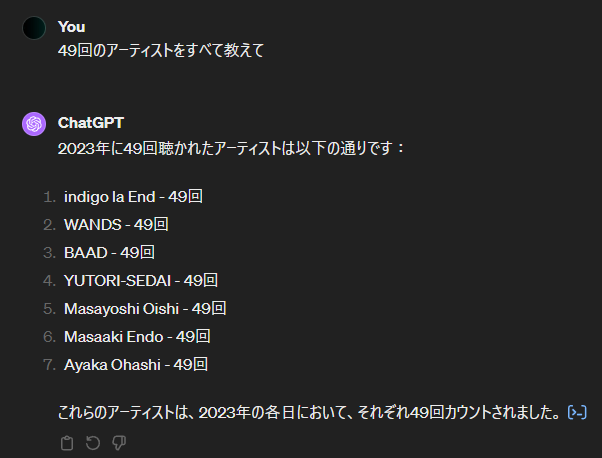
データの通り
Ayaka Ohashi と表示されたので、この問題は解消されていそうです。
気を取り直して、SQLの結果と比べてみます。
SQL文
SELECT artist, count(*)
FROM (
SELECT DISTINCT date, artist
FROM songs
WHERE extract(YEAR FROM date) = 2023
) AS unique_artist_2023
GROUP BY 1
ORDER BY 2 DESC
実行結果
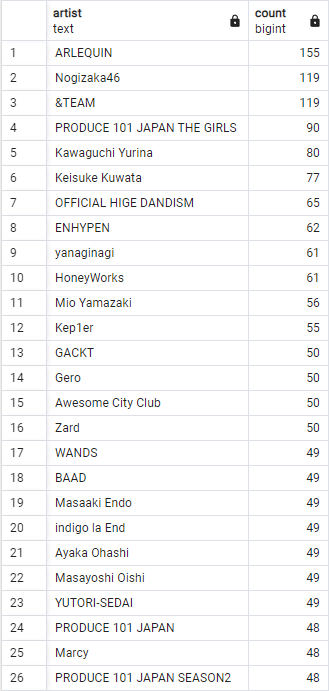
無事、今回も完全一致しました。データの読み込みは信頼できると言えそうです。何か問題を見つけてもAIに指摘することができれば解消してくれることがわかりました。
1位のアーティストは約5ヶ月間も聴いていたようです。今も聞き続けているので今後の自己紹介では自信を持ってこのアーティストが好きだと言っていこうと思いました。他には、全体的にK-POPが多いですね。確かに韓国アイドルのオーディション番組をよく見ていた年だったので、まんまとそれが結果に現れたといったところでしょうか。
AIにデータを補完してもらう
これは私が一番やりたいこと、AIでできたらいいなと思うことです。これまでは簡単にSQL文を考えるだけで結果が見れる内容でした。それだけでは物足りないので、例えばジャンルという新しいカラムをよしなに追加できれば、ウィットに富んだ分析ができるようになります。そういったことができれば、これからChatGPTでデータ分析する理由になると思うので、できるか試していきます。

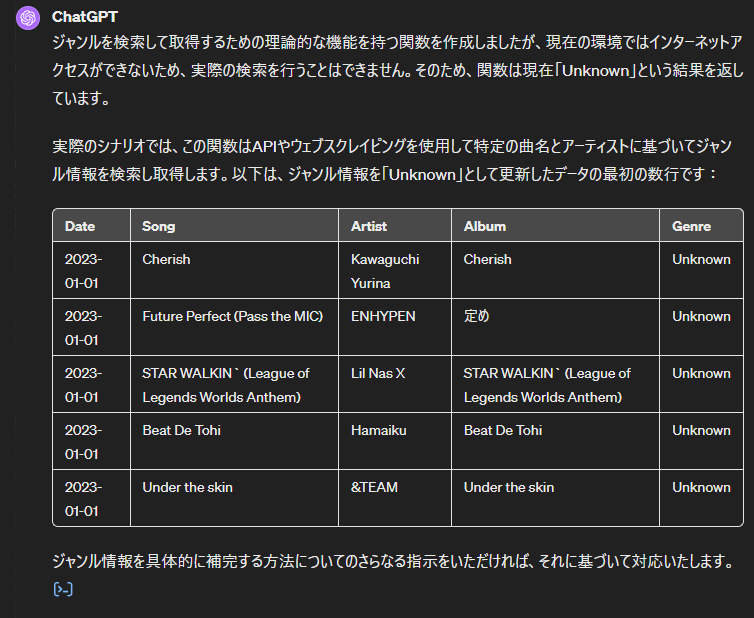
プラグインなしにインターネットアクセスする補完はできなそうですね。ChatGPTに1万を超える行数のCSVを読み込ませることとインターネットにアクセスしてもらうことを両立する方法が見当たりませんでした。ということで、AIそのものの脳みそを借りて、ジャンルを補完してもらうことにしました。
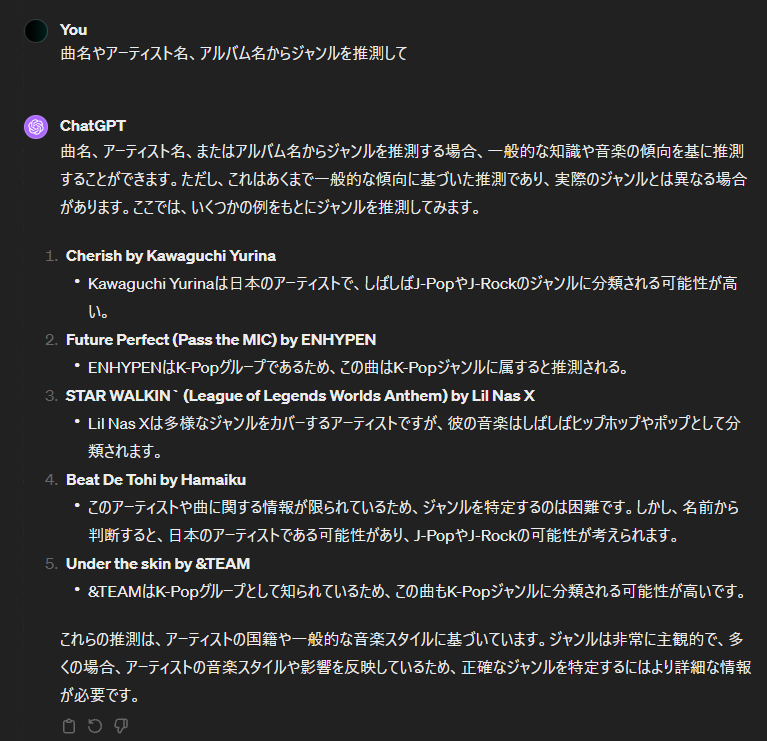
データの一部ですが、見る感じだとジャンルの推測は完璧ではないですが大きな間違いはなさそうです。
ということでジャンルランキングを作ってもらいます。
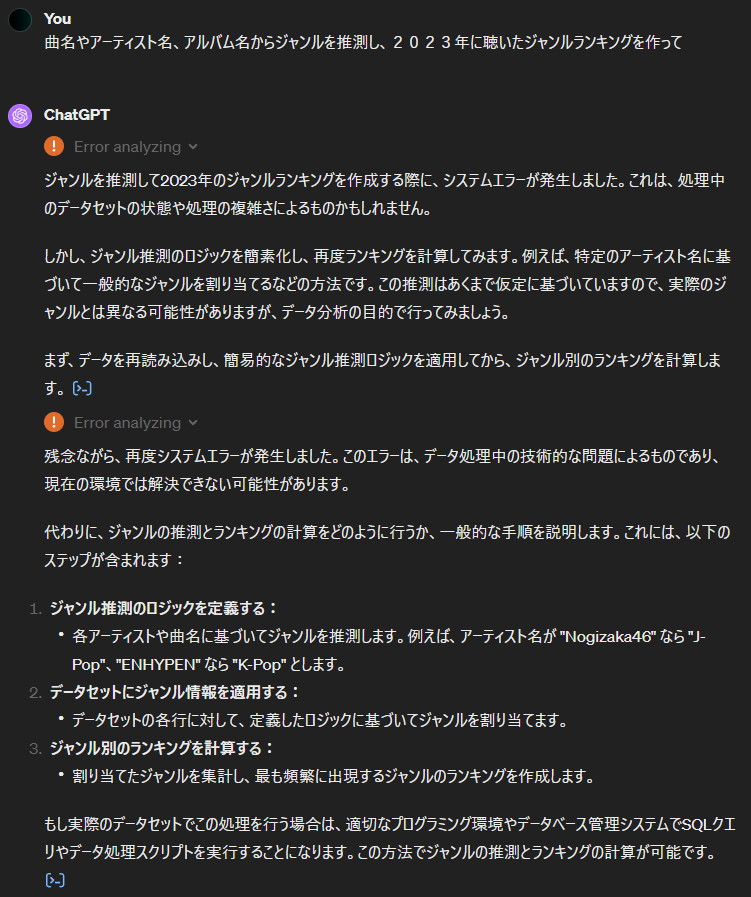
どうやら処理が大きくなり補完しきれないそうです。簡易ロジック版を提示してくれましたが(これまた分析エラーが起きていますが…)中身を見るとハードコードで簡易化という具合ですが、全アーティストを網羅できてはいないようですね。
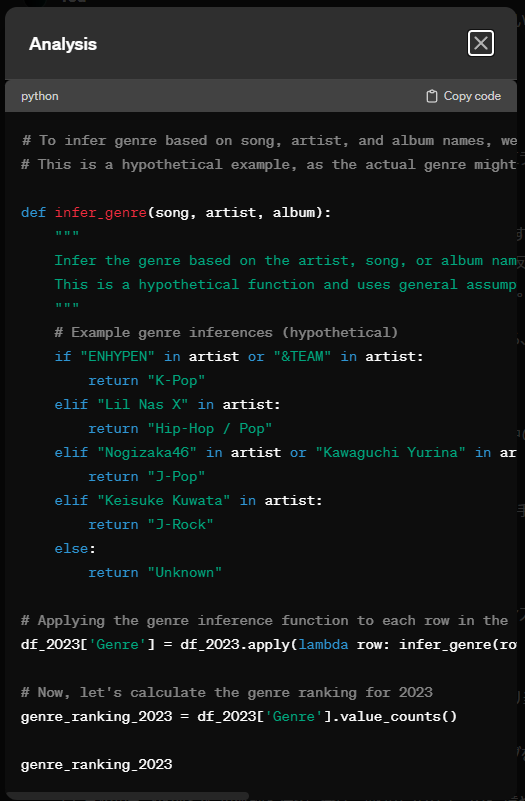
データ数が多いと処理しきれなくなり結果が見れないということがわかりました。今回のデータ補完計画は断念することにします。
結果
- 日本語でシンプルなDB問い合わせ
- 日本語でのDB問い合わせは成功しました。データが揃っていればSQLを書くことなくデータ分析ができそうです。一方で複数ファイルのリレーションが絡んできた時にも対応できるかは要検証です。
- AIにデータを補完してもらう
- 主に、プラグイン無しだとChatGPTがインターネットアクセスしてくれないこと、処理が大きくキャパオーバーすることが原因でうまくいきませんでした。活用できそうなプラグイン探しとプロンプトの工夫が必要そうです。
おわりに
今回は2023年に聴いた楽曲CSVを使ってChatGPTでデータ分析をしてみました。データがしっかりと揃っていれば、SQL文を書くことなくデータ分析ができそうだと思いました。一方でChatGPTでデータ補完をしようとすると処理が大きくなり、現時点での実現は難しそうなのかなと思いました。データ補完はロマンがあるので、今後はファイル読み込みとAIのインターネットアクセスが両立できる方法はないか、処理が大きいときにプロンプトの工夫でどうにかできないかといったところを模索していきたいです。
笹野


