この記事はレコチョク Advent Calendar 2021 の17日目の記事となります。
はじめに
はじめまして、新卒1年目エンジニアの柴田と申します。 音楽×データ分析に特化したグループに所属しており、現在はレコード会社向けのレポーティングサービス開発にてBIダッシュボードの作成を担当しています。
レコチョクでは音楽配信によるストアでの商品購入実績や配信サービスによる楽曲の再生実績データを集計し、コンテンツホルダー(レコード会社など)に提供するため、 データが閲覧できるWebサービスの開発を行っています。実績データをグラフや表の形式にまとめ、自動更新して提供するために、Amazon QuickSight (BIツール)を用いてBIダッシュボードを閲覧できるようにしています。
このサービスでは、開発過程の中で検証環境でデータの見え方を確認したり、コンテンツホルダーとダッシュボードのイメージを共有するため、モックアップを作成しています。モックアップを作るにはなんらかのデータが必要ですが、実際の実績データは情報漏洩のリスクやモラルの観点から利用すべきではないため、ダミーのデータを利用する必要があります。そのために、ダミーのデータを用いたダッシュボード(以後ダミーダッシュボードと呼ぶ)を作成し、モックアップとして使用しています。
本記事では、上記で紹介したダミーダッシュボードの作成フローについてまとめます。
ダミーダッシュボードの作成フロー
- ダミーデータ作成
- ダミーデータを生成する
- ダミーデータを CSV ファイル化する
- ダッシュボード作成
- データセットにダミーデータを準備する
- データセットを基に表やグラフを作成する
- 表やグラフをダッシュボードとして公開する
1 . ダミーデータ作成
今回のダミーデータ作成にはプログラミング言語 Python を使用しました。
開発環境 Python 3.9.7
ダミーデータの生成には Faker を使用することにしました。 Faker とはダミーデータを生成する Python のパッケージです。
Faker を使用するとランダムで名前、住所、電話番号、会社名、職業と幅広いダミーデータを自動生成することができます。
詳しくはFakerドキュメントをチェックしてみてください。
ダミーデータを生成する
まず、 Faker をインポートし、@dataclass で今回作成するダミーデータのデータ型を明記します。
class AlbumData:ダミーのアルバムメタ情報
class RawData:アルバムの販売実績データ
from dataclasses import dataclass
@dataclass
class AlbumData:
album_title: str // アルバムタイトル
artist_name: str // アーティスト名
ch_number: str // レコード会社の登録番号
company_name: str // レコード会社名
album_price: int = 2000 // アルバムの値段
@dataclass
class RawData:
artist_name: str // アーティスト名
title: str // タイトル
ch_number: str // レコード会社の登録番号
company_name: str // レコード会社名
report_month: str // 対象月
content_type: str // 販売コンテンツタイプ
sales_price: int // アルバム販売利益
sales_count: int // アルバム販売数
ここからダミーデータを生成していきます。
関数
generate_dummy_album()を作り、その中でダミーデータの言語指定をしてから単語を生成します。
Faker("ja_JP"):日本語のデータを対象とする
fake.words():単語リストを生成
from faker import Faker
def generate_dummy_album():
fake = Faker("ja_JP")
display_album_title = "".join(fake.words())
dummy_album = AlbumData(
album_title=display_album_title,
artist_name=fake.user_name(),
ch_number="dummy",
company_name="DUMMY",
album_price=2000,
)
return dummy_album
次に月毎のアルバムの販売実績データを生成します。
関数
generate_dummy_album()を基に対象終了月になるまでアルバムの販売実績データを生成します。
from_dt:販売実績データの対象開始月 (datetime 型)
to_dt:販売実績データの対象終了月 (datetime 型)
import random
from dataclasses import asdict, fields
import pandas as pd
from dateutil.relativedelta import relativedelta
df = pd.DataFrame(columns=[x.name for x in fields(RawData)])
target_date = from_dt
dummy_album = generate_dummy_album()
while from_dt <= target_date <= to_dt:
sales_count = random.randint(1, 100000)
tmp_report = RawData(
artist_name=dummy_album.artist_name,
title=dummy_album.album_title,
ch_number="dummy",
company_name="DUMMY",
report_month=target_date.strftime("%Y%m"),
content_type="album",
sales_price=sales_count * dummy_album.album_price,
sales_count=sales_count,
)
df = df.append(asdict(tmp_report), ignore_index=True)
target_date = target_date + relativedelta(months=1)
ダミーデータを CSV ファイル化する
最後に
df.to_csv()でdfの中身を CSV ファイルに書き出し、保存します。
df.to_csv([ファイル名].csv, index=False)
下記のように CSV ファイルにデータが書き出されていたらダミーデータの生成は完了です。
artist_name,title,ch_code,company_name,report_month,content_type,sales_price,sales_count
琥珀,マリン,dummy,DUMMY,202104,album,565528000,282764
琥珀,学生,dummy,DUMMY,202104,album,454544000,227272
琥珀,建築中世合計,dummy,DUMMY,202104,album,321065000,128426
琥珀,意図動物リニア,dummy,DUMMY,202104,album,25209750,100839
琥珀,野球,dummy,DUMMY,202104,album,58258000,29129
...
2 . ダッシュボード作成
ダミーデータを基に Amazon QuickSight でダッシュボードを作成します。 今回は CSV ファイルをアップロードするので「ファイルのアップロード」を選択します。
データセットにダミーデータを準備する
まず、作成したダミーデータを Amazon QuickSight にアップロードします。
ファイルのアップロード
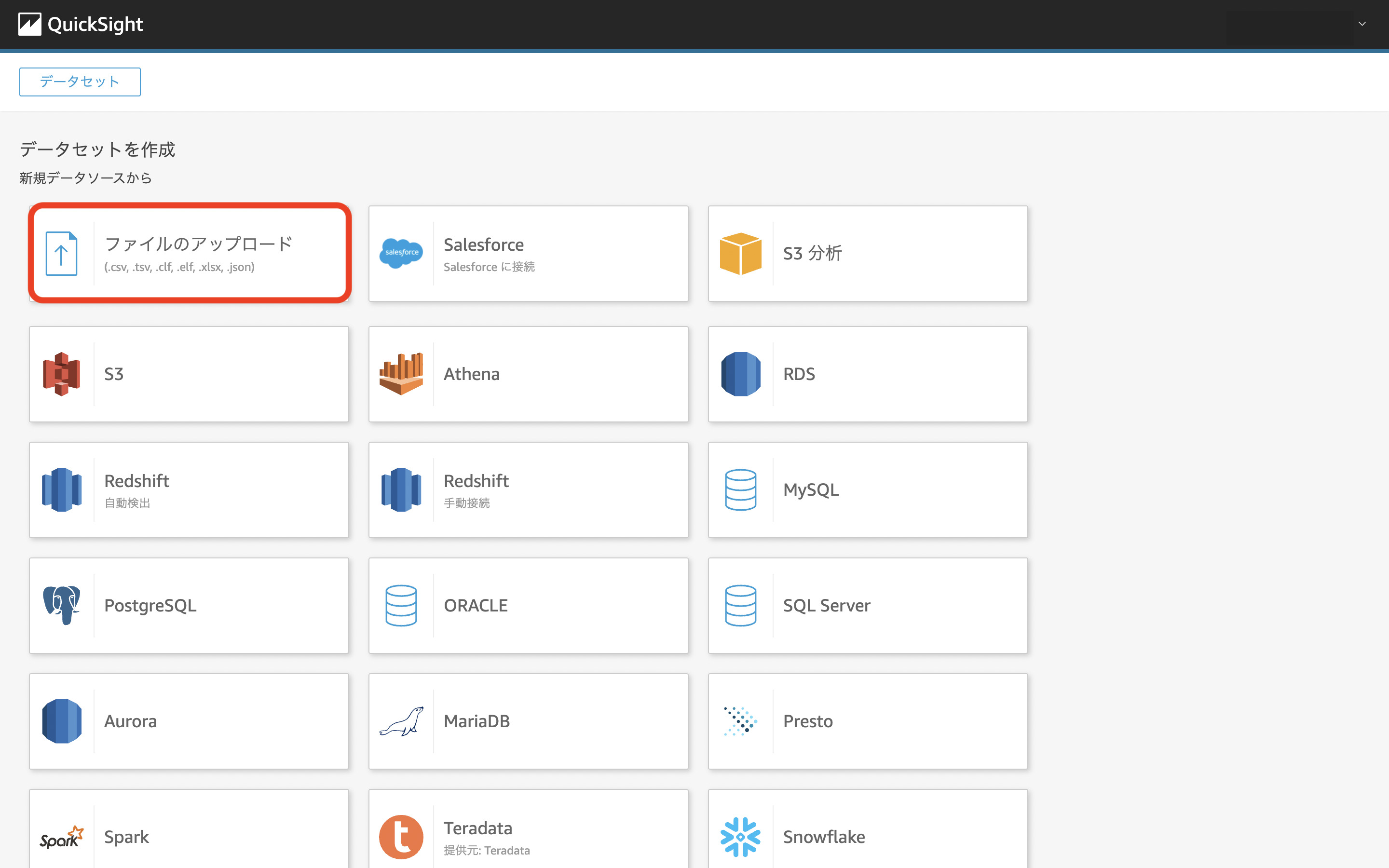
参考 データセットの作成
ダミーデータを基に表やグラフを作成する
ダミーデータをアップロードできたら、次は表やグラフを作成します。 Amazon QuickSight では、表やグラフの作成を「分析」で行います。
分析のページ
分析では、使用する表やグラフの種類選び、使用するデータの選択、タイトルなどの細い設定を行います。そして、データを見せたい形に整えられたら完成したものをダッシュボード化します。
データを表やグラフに整える
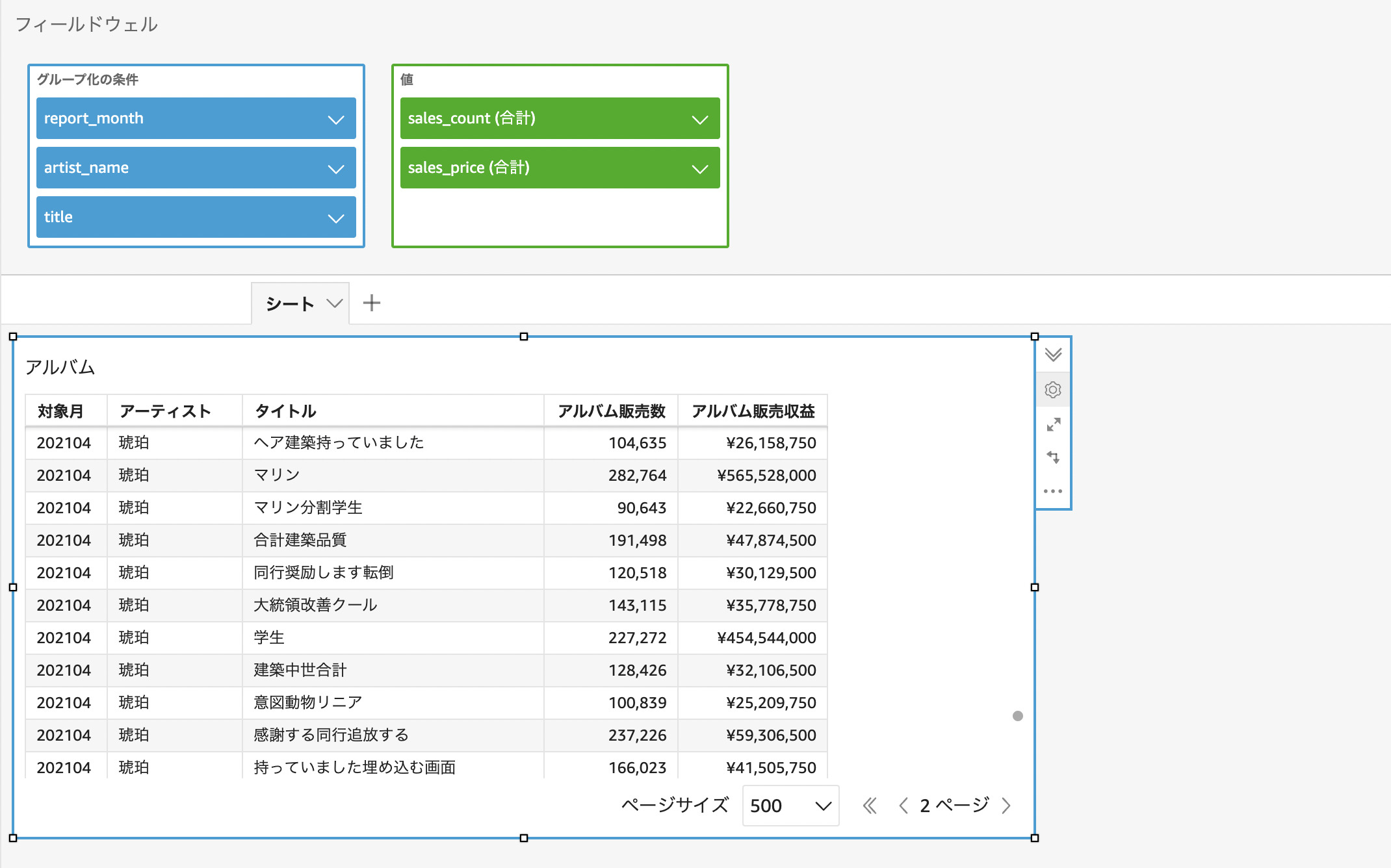
表やグラフをダッシュボードとして公開する
分析の「共有」から「ダッシュボードの公開」をクリック、名前を入力後「ダッシュボードの公開」をクリック
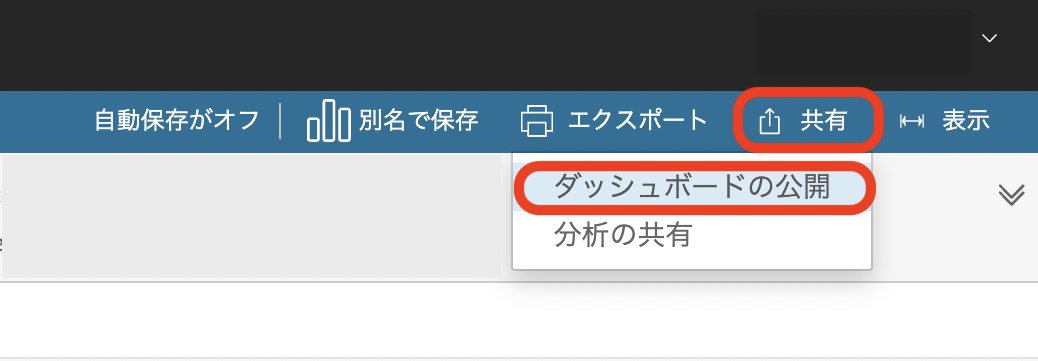
画像のようにダッシュボードの公開ができたら、ダミーダッシュボード作成は終了です。
困ったところ/工夫したところ
ダミーデータを何万件と生成していると、虐待 や 血まみれ といったアルバムのタイトルにするには良くないネガティブな単語がいくつか含まれていました。 そのまま使用するとコンテンツホルダーへモックアップをお見せするとき、印象が悪く好ましくありません。 そこで、ネガティブな単語を集めたリスト(以後ネガティブ単語リストと呼ぶ)を作成し、リストアップされたネガティブ単語は除外する工夫を加えました。
具体的には、今まで
fake.words()でネガティブな単語も含まれた単語のリストが生成されていたので、
ネガティブ単語リストにある単語は除いた単語のリストを返却する関数
get_not_negative_wordsを作成し、それを使用するようにしました。
from faker import Faker
negative_words = [
"虐待",
"怒り",
"犯罪者",
"血まみれの",
"助けて",
"ダニ",
]
def is_negative_word(word: str):
return word in negative_words
def get_not_negative_words(fake: Faker, nb: int):
words = []
while len(words) != nb:
target_word = fake.word()
if not is_negative_word(target_word):
words.append(target_word)
return words
使用したパッケージやサービスについて
Faker ではネガティブな単語が出てくることに困りましたが、言語指定をしてメソッドを呼び出すと簡単にダミーデータを生成できる点は便利に感じました。 また、幅広い種類のダミーデータが生成できるのであらゆる業界で活用できるパッケージだと思います。
Amazon QuickSight はデザインがシンプルで操作性が良いと感じました。 ボタン一つ押しただけで、どういうことをするか直感的に理解ができるので初めて触る方も使いやすいと思います。
おわりに
今回、ダミーデータの生成からBIダッシュボードの作成までを行い、ダミーデータは幅広く活用できることを学びました。 また、今回使用した Faker や Python 、Amazon QuickSight の理解を深めることもできました。
ダミーデータを用いたBIダッシュボードは、今回のような検証環境のモックアップが必要となるようなシーンで役立ちます。 本記事の内容がみなさんのお役に立てれば幸いです。
最後まで読んでいただきありがとうございました。
明日のレコチョク Advent Calendar 2021は18日目「 【Swift】プロトコル(protocol)の使い方」です。お楽しみに!
参考
柴田帆乃香

