はじめに
システム開発推進部第1Gの牧野です。 昨今、生成AIが急速に発達し、様々なサービスが登場していますが、それに伴い、利用する上でセキュリティ面やコスト面の課題が生じていると感じました。 そこで今回は、LLMをローカルで動かすことでこれらの課題が解決できるかどうかを検証しました。
LLMをローカルで動かすメリット
LLMをローカルで動かすことには以下のメリットがあると考えています。
- コスト面の課題解決:
- 無料でも利用可能ですが、APIを使って生成AIを特定の処理に組み込むと料金が発生します。ローカルで動かせばAPI不要で生成AIを活用できます。
- セキュリティ面の課題解決:
- 機密文書を外部の生成AIに読み込ませることができなかったり、社外への情報漏洩が懸念されたりする場合に有効です。
- 自由度:
- 公開されていないLLMを自分で自由に扱うことができます。
LLMをローカルで動かす方法
LLMをローカルで起動する基本的な方法は、公開されている学習済みのモデルをローカルにダウンロードし、Pythonのtransformersやtorchといった機械学習系ライブラリを利用して起動します。 調べた結果、以下の手法が主流のようです。
- llama-cppを利用する。
- llama-cpp-pythonを利用する。
- Lmstudioを利用する。
今回はllama-cpp-pythonを利用して検証を進めます。 ※なお、Pythonとpip(パッケージ管理システム)がインストールされていることを前提とします。
llama-cpp-pythonを利用してLLMをローカルで動かす
学習済みのLLMをhugging face1からダウンロードします。 今回は、日本語対応であり、比較的新しいモデルであるElyza(Meta社のLlamaをベースにしたLLM)のLlama-3-ELYZA-JP-8Bを使用します。また、llama-cpp-pythonを利用する方法では量子化2されたLLMが必要なため、このモデルの量子化バージョン(.gguf)を使用します。 以下からLlama-3-ELYZA-JP-8B-q4_k_m.ggufをダウンロードします。 https://huggingface.co/elyza/Llama-3-ELYZA-JP-8B-GGUF/tree/main
まずPythonが動く環境を用意します。
任意のディレクトリ(project dir)配下に任意のプロジェクト名(newenvname)を作成します。
Pythonやpipコマンドを使用するときはアクティベートが必要なので使用する前に1度だけ
source [newenvname]/bin/activateを実行する必要があります。
cd [project dir]
python3 -m venv [newenvname]
#pythonやpipコマンド使用前に1度実施する
source [newenvname]/bin/activate
次にllama-cpp-pythonが必要なためインストールします。
pip install llama-cpp-python
以下の内容で.pyファイルを作成します。 自分はllm-local.pyとしました。
from llama_cpp import Llama
llm = Llama(
model_path="[モデルがあるディレクトリ]/Llama-3-ELYZA-JP-8B-q4_k_m.gguf", # path to GGUF file
n_gpu_layers=0, # The number of layers to offload to GPU, if you have GPU acceleration available. Set to 0 if no GPU acceleration is available on your system.
)
prompt= [
{"role": "system", "content": "あなたは誠実で優秀な日本人のアシスタントです。特に指示が無い場合は、常に日本語で回答してください。"},
{"role": "user", "content": "今後の生成AIの進化について教えてください。"},
]
output = llm(
f"<|user|>\n{prompt}<|end|>\n<|assistant|>",
max_tokens=512,
stop=["<|end|>"],
echo=True,
)
print(output['choices'][0]['text'])
作成した.pyファイルを実行します。
python llm-local.py
結果が返ってきました。
<|user|>
[{'role': 'system', 'content': 'あなたは誠実で優秀な日本人のアシスタントです。特に指示が無い場合は、常に日本語で回答してください。'}, {'role': 'user', 'content': '今後の生成AIの進化について教えてください。'}]<|end|>
<|assistant|>生成AIの進化は、年々加速して進んでいます。特に近年は、AIの深層学習技術の向上、GPUの高性能化、ビッグデータの活用などが進み、AIの能力が著しく向上しています。以下に、生成AIの今後の進化の方向性をいくつか示します。
1. 自然言語処理の向上: 会話AIや生成AIが、より正確に、より理解しやすく、より創造的な文章や会話を生成するようになります。
2. 多モーダル処理の進化: 音声、画像、動画、テキストなど、複数のモーダルな入力データを組み合わせて処理する能力が向上し、より高度な多モーダル処理が可能になります。
3. 専門知識の拡充: AIが、特定のドメインや専門分野の知識を獲得する能力が向上し、より高度な知識を有するAIが生成されるようになります。
4. 自己改良能力の獲得: AIが、自ら学習データやアルゴリズムを改良する能力を獲得することで、自己成長を実現します。
5. 人間の能力を超えるAI: 将来的には、AIが人間の能力を超える領域に到達し、問題解決や創造性の面で人間の能力を超える可能性があります。
以上が、生成AIの今後の進化の方向性です。AIの進化は、社会のあらゆる面に影響を与えるため、我々はAIの進化の動向を注視し、適切な活用方法を模索する必要があります。
うまく使えているようです。 処理時間は40〜90秒ほどで応答が返ってきました。 (質問内容やPCスペック、実行時のメモリ状況によって変わると思いますのでご参考までに。私の使用しているPCはM1 MacBook Proのメモリ16GBです。)
ローカルLLMの使い道
使い方の一例をご紹介します。
私は、LLMに指定したジャンルのおすすめの曲を紹介してもらうことにしました。 ジャンルが毎回変わるようにいくつか用意し、ランダムに指定するようにしています。 今回は、cronでシェルスクリプトを定期実行させ、そのシェルからPythonを実行するため、質問内容と回答を渡すために
print(input_text+'\n\n'+assistant_text)としています。
以下ソースコードです。llm-local.pyから適宜修正しました。
recommend-miusic.py
from llama_cpp import Llama
import random
def begin(input_text):
llm = Llama(
model_path="[モデルがあるディレクトリ]/Llama-3-ELYZA-JP-8B-q4_k_m.gguf", # path to GGUF file
n_gpu_layers=0, # The number of layers to offload to GPU, if you have GPU acceleration available. Set to 0 if no GPU acceleration is available on your system.
)
prompt= [
{"role": "system", "content": "あなたは誠実で優秀な日本人のアシスタントです。特に指示が無い場合は、常に日本語で回答してください。"},
{"role": "user", "content": input_text},
]
output = llm(
f"<|user|>\n{prompt}<|end|>\n<|assistant|>",
max_tokens=512,
stop=["<|end|>"],
echo=True,
)
str = output['choices'][0]['text']
# '<|assistant|>'の位置を見つける
assistant_index = str.find('<|assistant|>')
# その位置以降の文字列を切り出す
assistant_text = str[assistant_index + len('<|assistant|>'):]
print(input_text+'\n\n'+assistant_text)
# 毎回ランダムに質問する
category = ["平成", "令和", "昭和", "夏", "冬", "K-POP", "邦楽", "洋楽"]
input_text = category[random.randint(0, len(category) - 1)]+"のおすすめの曲を1つ教えてください。"
begin(input_text)
次に作成した.pyをshellから実行させてその出力をダイアログで画面に表示させます。
sample.sh
source [binがあるディレクトリ]/bin/activate
result=$(python [.pyがあるディレクトリ]/recommend-musice.py)
#LLMの回答をダイアログで表示
osascript -e "display dialog \"$result\" buttons {\"OK\"} default button \"OK\""
最後に定期実行させるために作成した.shをcronで実行させるための設定をします。 今回は試しに1分間隔で実行させてみます。
#作成した.shファイルに権限を追加
chmod +x [.shがあるディレクトリ]/sample.sh
#crontab -eで* * * * * [.shがあるディレクトリ]/sample.shと入力する
crontab -e
#crontab に適切に設定できているか確認
crontab -l
#* * * * * [.shがあるディレクトリ]/sample.shとなっていることを確認する
#毎分実行するように設定
定期実行で動かしてみました。
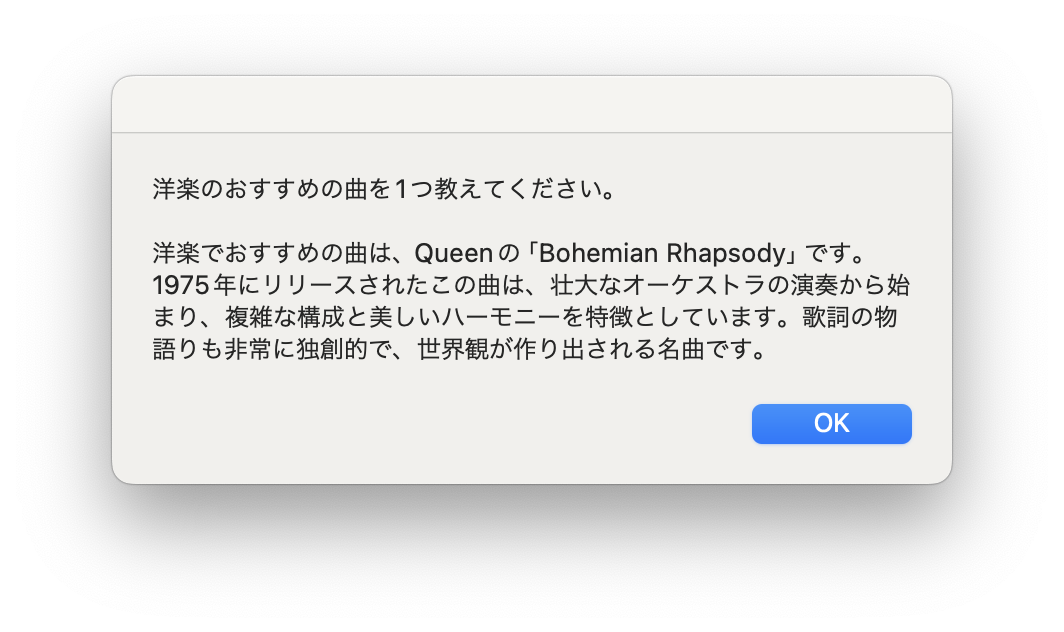
いい感じですね! 曲の紹介とその曲に関する情報も簡単に教えてくれました。 観察を続けたところ、同じジャンルでも異なる曲を紹介してくれるので、問題なさそうです。 私は昼休憩後に眠くなることがあり、音楽を聴くことがあります。そのため、昼休憩後の時間帯に設定して実行すれば、活用できそうだと思いました。
まとめ
今回はローカルでLLMを動かし、その使い道を模索しました。作成した便利ツールとしての使い方も良いですが、業務の効率を上げるような使い方ができればさらに有用だと思いました。 より性能の良いLLMをローカルで動かせるようになり、回答の質や処理速度が向上すれば、使用範囲が広がり、コスト面やセキュリティ面の課題が解決に進むと感じました。 また、定期実行でLLMを動かす際、API利用の場合は料金が発生しますが、ローカルで動かすLLMであれば料金が発生しないため、定期実行×ローカルLLMの組み合わせはローカルで動かす利点を最大限に活かせると思います。
参考元
ローカルLLM”Phi-3″をWindows CPUで動かす LLMをローカル環境で動かすことは貴族の遊びなのか? LMstudioをローカルマシン上で使ってみる huggingface elyza/Llama-3-ELYZA-JP-8B-GGUF
牧野拓海


